
Posted on July 17th, 2019

Company name data is inherently inconsistent. This can be a significant problem when company names are collected and stored in a database. Aggregating and reporting on data by company name when data is unstandardized can negatively impact business intelligence activities that rely upon such reporting for strategic decision-making. It also often leads to duplicate records within databases, fragmenting internal information about a given organization. How can this be addressed using Interzoid's Similarity Key technology?
Company name data, as well as any textual data, can be represented in customer or vendor data stores by one of many permutations of data that exists for a given entity. For example, "IBM", "International Business Machines", and "IBM Corp" are all versions of the company we all know as Big Blue. The names "GE", "Gen. Electric", and "General Electric" are another example of inconsistent organizational name entities. Also, words like "the", "inc", "incorporated", "incorporation", and "Ltd" make it more difficult to match, sort, and report on company name data.
An approach to solving this problem is using an algorithmically generated "Similarity Key" that addresses the company name data inconsistency issue. The keys are generated for a given data value using similarity trees, smart hashing, heuristics, and various forms of artificial intelligence, including knowledge representation and reinforcement learning. These generated keys then assist in the identity of inconsistent forms of data that represent the same piece of information.
Typically, a Similarity Key is generated for the company name field in a database. It is then stored either as a new column in the same table, or in a new table with a reference back to the original record. The generated Similarity Key essentially looks like a hash value (a string of characters and numbers).
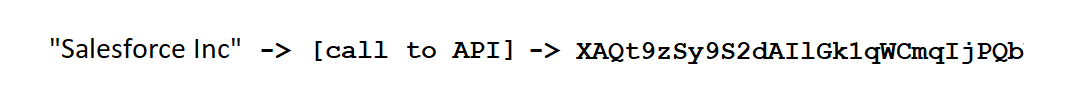
If the generated keys are then stored as columns within a table (or possibly as a key-value pair within non-SQL data stores), then sorting the table by Similarity Key will enable similar records to appear next to each other, either for the purposes of compiling a match report, for automated processing of redundancy, or for the opportunity to visually inspect candidate duplicate records.
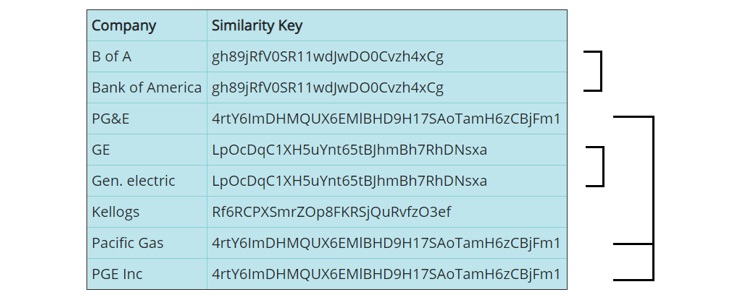
If the use case is matching company data across multiple tables or data sources as part of a data merge, then using the Similarity Key as the basis of the match (or join) will yield a significantly greater number of intelligently identified matches rather than just matching on an unstandardized organizational name field, in which case match rates will likely be very low.
The only thing required to ameliorate the challenge of redundant company name data with Similarity Keys is to programmatically send records to the Company Name Match API one name at a time. Not only can you then customize your approach to dealing with the issue, it makes it easy to utilize the same solution with multiple data sources and use cases including data that is independently-stored or otherwise accessible within internal or Cloud-based applications.
All content (c) 2018-2023 Interzoid Incorporated. Questions? Contact support@interzoid.com
201 Spear Street, Suite 1100, San Francisco, CA 94105-6164
Interested in Data Cleansing Services?
Let us put our Generative AI-enhanced data tools and processes to work for you.
Start Here
Terms of Service
Privacy Policy
Use the Interzoid Cloud Connect Data Platform and Start to Supercharge your Cloud Data now.
Connect to your data and
start running data analysis reports in minutes: connect.interzoid.com
API Integration Examples and SDKs: github.com/interzoid
Documentation and Overview: Docs site
Interzoid Product and Technology Newsletter: Subscribe
Partnership Interest? Inquire