Business Intelligence - Is the Underlying Data Suspect?
Posted on October 20th, 2022
How useful are business intelligence applications if the underlying data is suspect?
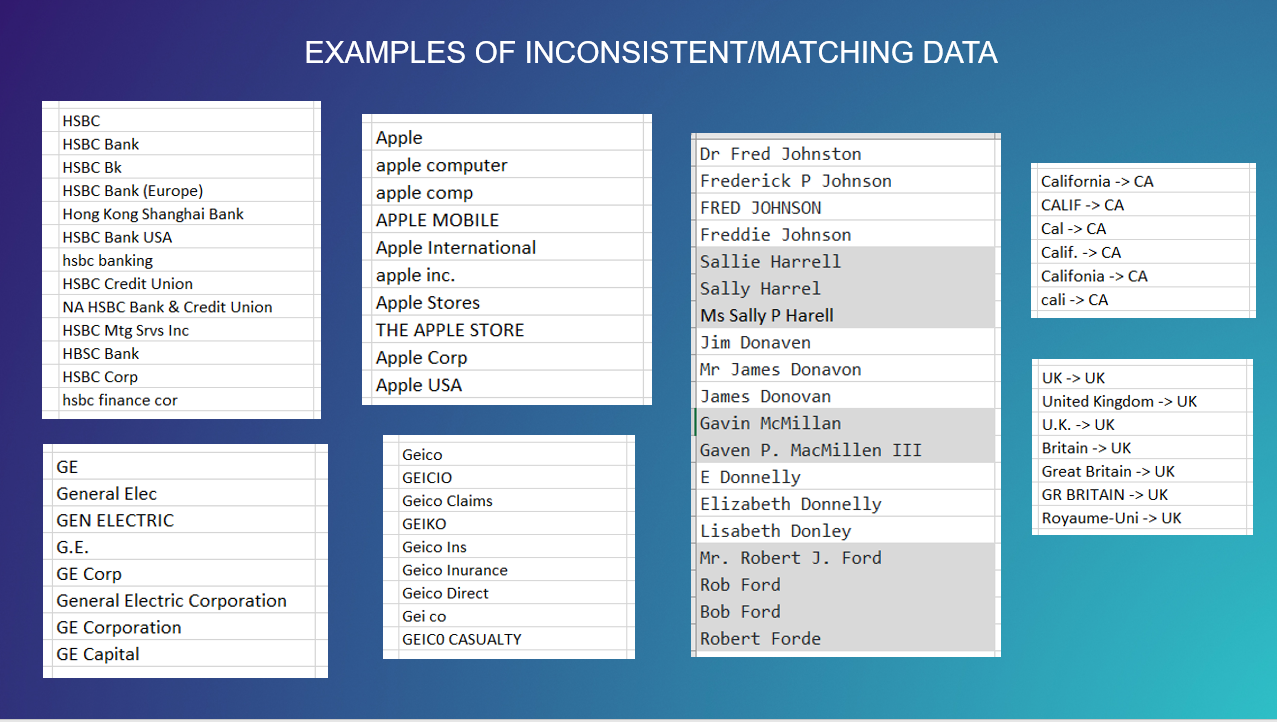
Inconsistently represented data is often at the root of an organization's data challenges. This means the same piece of information, such as an organization name, can be present under a multitude if permutations within various datasets. If this issue is unaddressed in the various data tables used to feed business intelligence applications, the analysis obtained from these applications can be significantly off. That can lead to poor decision-making.
Some examples:
Fortunately, using Interzoid's various data matching APIs and similarity key technology, these challenges can be greatly simplified, if not solved entirely.
Interzoid's data-type-specific Matching APIs enable a hash-based "similarity key" to be algorithmically generated by traversing similarity trees that have been creating utilizing heuristics, phonetics, specific language knowledge, spelling variation analysis, AI-based learning methods, and rich data content-specific reference databases. These similarity keys are then used as the basis of all data matching, enabling variations of similar data, such as "Jim" and "James", "Street" and "St", and "Inc." and "Incorporated" to be identified across data fields. The similarity key approach allows ultimate flexibility in terms of how identified matches are dealt with and for easy integration into a wide range of data-driven applications.
With the Interzoid Matching APIs, you can:
✔ Eliminate redundant and duplicate data from customer and
important
databases
✔ Leverage data content-specific matching algorithms for higher matching success rates
✔ Improve the accuracy of data analysis activities with better, more accurate foundational
data
✔ Utilize fuzzy matching to match data across datasets
✔ Enable fuzzy searching for better, more comprehensive search results
✔ Achieve greater ROI with business intelligence investments
✔ Leverage growing AI-driven knowledge bases of matching and inconsistent data identification
✔ Reduce costs associated with redundant, duplicate data
✔ API-based solution enables full customization of data matching strategies
✔ Data connectivity tools allow native connections for easy match identification
reporting
✔ Similarity keys can be leveraged within a broad range of applications
✔ Easy to get up-and-running with immediate results
AI Interactive Data Client: Request and Receive Structured Data of Any Kind on Any Subject.
More...
Github Code Examples
More...
Generate your own Datasets: Retrieve Customized, Real-World Data on Demand as Defined by You
More...
High-Performance Batch Processing: Call our APIs with Text Files as Input.
More...
Try our Pay-as-you-Go Option
More...
Available in the AWS Marketplace.
More...
Free Trial Usage Credits
Check out our full list of AI-powered APIs
More...
Documentation and Overview
More...
Product Newsletter
More...