The Value of Consistent Data
When datasets contain inconsistencies—such as misspelled names, varying abbreviations, or different formats—finding accurate matches and extracting meaningful insights becomes challenging. This lack of consistency can lead to:
- Duplicate Data: Multiple entries for the same entity under different names or formats.
- Misaligned Insights: Inaccuracies in data can lead to erroneous analytics and decision-making.
- Inefficient Data Operations: Repeated manual efforts to clean and standardize data waste resources and increase costs.
To address these challenges, organizations need a systematic and automated approach to identify and reconcile inconsistencies. That’s where Interzoid’s APIs, combined with JSON input capabilities, come into play.
Solving Data Consistency Challenges with JSON and Interzoid APIs
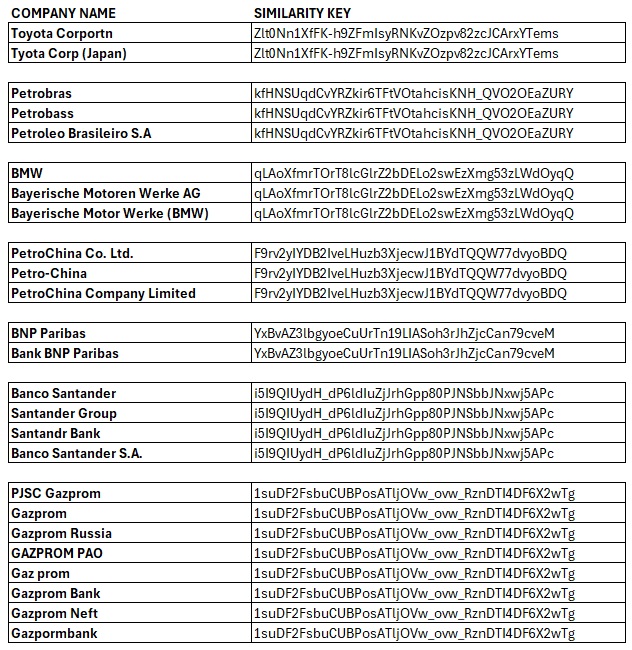
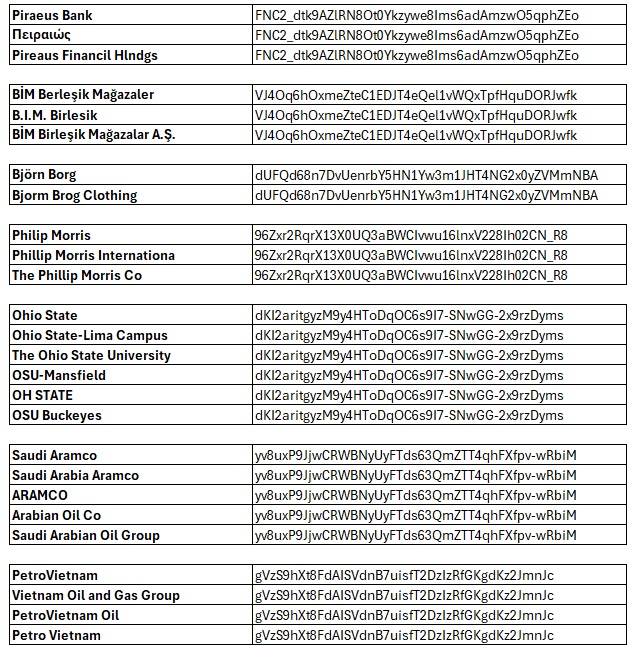
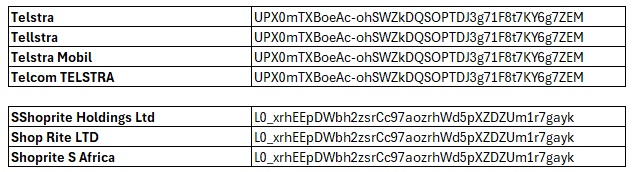
Interzoid’s Matching APIs are designed to identify and manage inconsistencies by generating similarity keys for data content values and then sorting and comparing by them. These keys can help pinpoint variations in names, addresses, and other data fields that refer to the same entity. By using AI-powered technology, Interzoid’s APIs create similarity keys based on textual analysis, enabling organizations to detect and consolidate duplicated or inconsistent entries effectively.
Why JSON?
JSON (JavaScript Object Notation) is a lightweight data-interchange format that's easy to read and write for humans and machines alike. It provides a standardized way to input data, which makes it ideal for handling datasets that require data consistency validation. By utilizing JSON, Interzoid’s APIs can efficiently process and match records in bulk.
Here’s how JSON plays a role in achieving consistent and usable datasets:
- Batch Processing of Data: The Full Dataset Matching API supports JSON input in batch mode, allowing organizations to input up to 100 values at a time. This makes it possible to quickly analyze and generate similarity keys across large datasets without having to provide files.
- Flexibility with Reference Values: JSON input can also include reference values that map directly to primary keys or record identifiers, making the matching results easier to align with the original dataset.
How It Works
To leverage JSON with Interzoid’s Matching APIs, users can supply the input data as JSON objects. Below are two common scenarios that demonstrate how JSON is used:
Example 1: JSON Batch Input without a Reference Value
For identifying inconsistent data, JSON structured values can be submitted for analysis, as shown below:
[
{ "Data": "IBM" },
{ "Data": "International Business Machines" },
{ "Data": "ibm corp" }
]This data can be URL-encoded and passed to the API for processing, like this:
%5B%7B%22Data%22%3A%22IBM%22%7D%2C%7B%22Data%22%3A%22International%20Business%20Machines%22%7D%2C%7B%22Data%22%3A%22ibm%20corp%22%7D%5D
And here is an actual API call that generates similarity keys for each of the entities within the encoded JSON:
curl "https://connect.interzoid.com/run?function=match&your-api-key&source=jsonbatch&data=%5B%7B%22Data%22%3A%22IBM%22%7D%2C%7B%22Data%22%3A%22International%20Business%20Machines%22%7D%2C%7B%22Data%22%3A%22ibm%20corp%22%7D%5D&category=company&process=keysonly&table=jsonbatch&keysoutputall=true&target=json"
Example 2: JSON Batch Input with a Reference Value
When including a reference value, the input JSON might look like this:
[
{ "Data": "IBM", "Reference": "376152" },
{ "Data": "International Business Machines", "Reference": "419044" },
{ "Data": "ibm corp", "Reference": "277383" }
]The URL-encoded version would be used with the API as follows:
%5B%7B%22Data%22%3A%22IBM%22%2C%22Reference%22%3A%22376152%22%7D%2C%7B%22Data%22%3A%22International%20Business%20Machines%22%2C%22Reference%22%3A%22419044%22%7D%2C%7B%22Data%22%3A%22%22%2C%22Reference%22%3A%22277383%22%7D%5D
And here is an actual API call that generates similarity keys for each of the entities within the encoded JSON, this time also using a reference value (such as a primary key) to display with the similarity key:
curl "https://connect.interzoid.com/run?function=match&apikey=your-api-key&source=jsonrefbatch&data=%5B%7B%22Data%22%3A%22IBM%22%2C%22Reference%22%3A%22376152%22%7D%2C%7B%22Data%22%3A%22International%20Business%20Machines%22%2C%22Reference%22%3A%22419044%22%7D%2C%7B%22Data%22%3A%22%22%2C%22Reference%22%3A%22277383%22%7D%5D&category=company&process=keysonly&table=jsonrefbatch&keysoutputall=true&target=json"
By making batch API calls with JSON input, organizations can quickly analyze data, generate similarity keys, and address data inconsistencies without the need for cumbersome file uploads or manual interventions.
Take the Next Step
Interzoid’s Full Dataset Matching APIs, combined with the simplicity and flexibility of JSON input, offer organizations an efficient way to unlock the full value of their data assets. With batch processing capabilities and AI-powered similarity key generation, it's easier and faster than ever to solve issues of data inconsistency, duplication, and usability.
To learn more about using JSON with Interzoid's Full Dataset APIs, including detailed documentation and examples, visit Interzoid's Data Matching Workflow and Full Dataset Matching API.
By focusing on data consistency and leveraging powerful matching technology, organizations can ensure the integrity of their datasets and make data-driven decisions with confidence. JSON input, combined with Interzoid’s APIs, provides the key to unlocking data quality at scale.