Databricks Connectivity Now Available
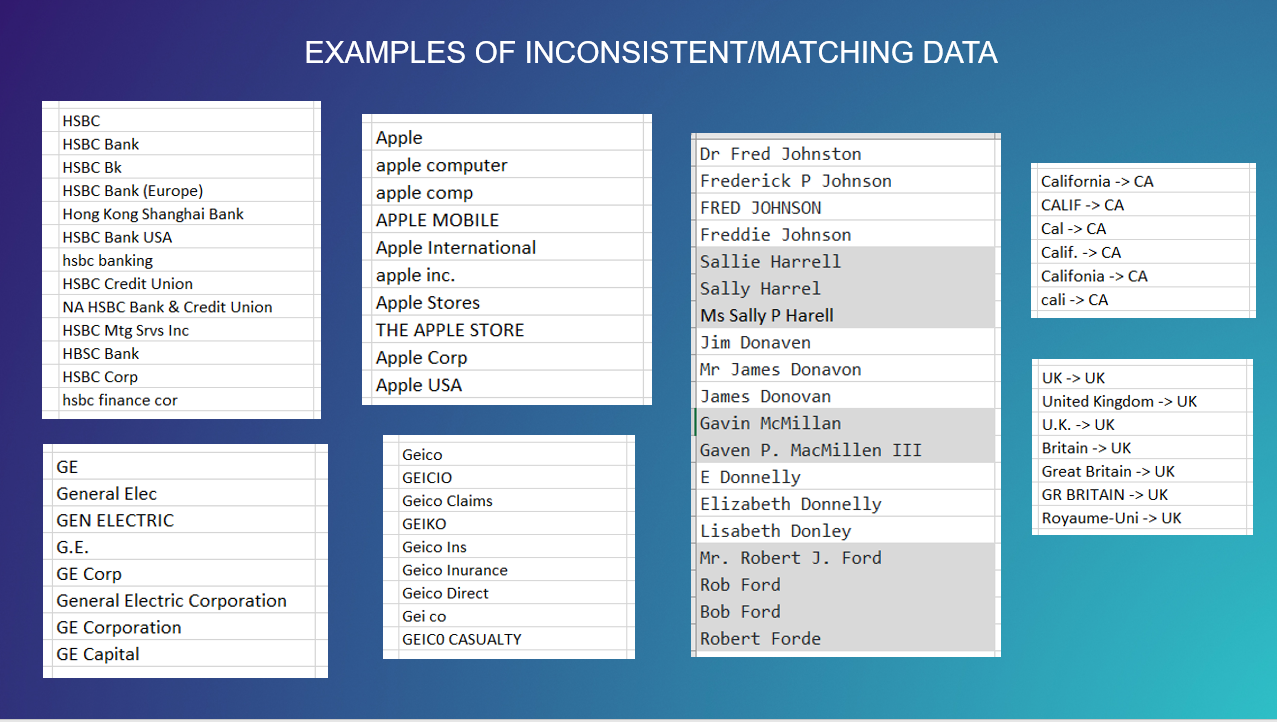
Run matching/duplicate data reports, identify inconsistent data, enrich data, and more within Databricks clusters and SQL warehouses.
The Databricks platform provides a cloud-based environment that combines data processing, analytics, and machine learning for datasets. It allows data engineers, data scientists, and analysts to work collaboratively on data projects. The platform is designed to handle large-scale data processing tasks and provides support for various programming languages such as Python, R, Scala, and SQL.
Interzoid's Cloud Data Connect application now has the ability to natively connect to Databricks clusters and SQL warehouses, enabling the running of match reports to identify redundant entity and individual names (within a dataframe for example), add similarity keys for intelligent data joins, enrich data with third-party data, validate data, and more.
For example, to run a match report against data within Databricks, click here.
You will need the following to access your data within Databricks:
- Server Hostname
- Port
- HTTP Path
- Personal Access Token
You will use this as part of a Databricks connection string, enabling connectivity to begin running data quality and analysis reports.
Questions? Contact us at support@interzoid.com
AI Interactive Data Client: Request and Receive Structured Data of Any Kind on Any Subject.
More...
Github Code Examples
More...
Generate your own Datasets: Retrieve Customized, Real-World Data on Demand as Defined by You
More...
High-Performance Batch Processing: Call our APIs with Text Files as Input.
More...
Try our Pay-as-you-Go Option
More...
Available in the AWS Marketplace.
More...
Free Trial Usage Credits
Check out our full list of AI-powered APIs
More...
Documentation and Overview
More...
Product Newsletter
More...