Databricks Interzoid Company Name Matching Tutorial
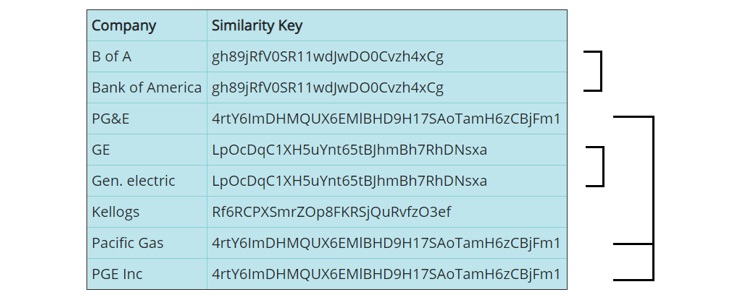
Identify Inconsistent/Matching Company Names in a Dataset or Data Table within Databricks using DataFrames and an easy-to-use API from Interzoid.
In the tutorial, you will create a workspace "notebook" within the Databricks free Community Edition, load a CSV file into a Delta table (Deltabricks SQL data store), and create a function that accesses the Interzoid Company Name Match Similarity Key API for each record in the table. You will then reference the Delta table via DataFrames to append similarity keys to each record, and then use those similarity keys to overcome inconsistent data and identify duplicate/matching company names.
This same process of course can be used with your own files and data tables to identify and resolve duplicate/redundant data caused by inconsistent data representation, so everything you do with your data is more effective, valuable, and successful.
You will need to have an Interzoid API key to execute the notebook. You can register with your email address here. You will receive enough free trial credits to perform the matching processes in the tutorial.
Step 1: Create a Databricks free Community Edition account if you do not yet have one:
https://databricks.com/try-databricks
Then, log in to your account https://community.cloud.databricks.com/login.html
Step 2: Create a new Notebook. This will be your workspace.

Step 3: Since you probably do not already have a cluster running, you will be asked to create the resource. Note that in the Community Edition, a cluster's resources will be released after two hours of idle time. If this happens, you will just need to create and reattach to a new cluster resource and resume your work.
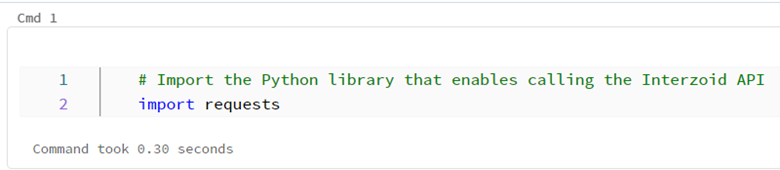
Step 4: The first command you will want to issue in your noteback will be to import the Python library package that will be used to enable the calling of the Interzoid API. Simply type the command into the notebook, and then [Shift]+[Enter] will execute the command and load the necessary library.
# Import the Python library that enables calling the Interzoid API
import requests
Here is an example of what executing the command looks like within Databricks. However, so you can cut and paste the commands, we won't show this for each step and show the code instead. It's just to make sure you are executing commands in the Notebook properly.
Step 5: Next we need to define the function that will call the Interzoid API for each row in our table by entering the following into the Notebook. Don't forget [Shift]+[Enter] to execute the command within the Notebook like in Step 4.
# Define the function that will call the Interzoid Company Name Matching API for each row (register for your API key at www.interzoid.com)
def match(s):
response = requests.get('https://api.interzoid.com/getcompanymatchadvanced?license=YOUR_API_KEY&company='+s+'&algorithm=wide')
if response.status_code == 200:
data = response.json()
return data["SimKey"]
else:
return "error"
Step 6: Next download the CSV file of company names to your local machine that we will use for the tutorial. The file is located here: https://dl.interzoid.com/csv/companies.csv (2.7k)
Step 7: Now we need to import the CSV file into a Databricks Delta table using the "Create Table" import UI.
On the Create Table UI, under Files do 'click to browse'.
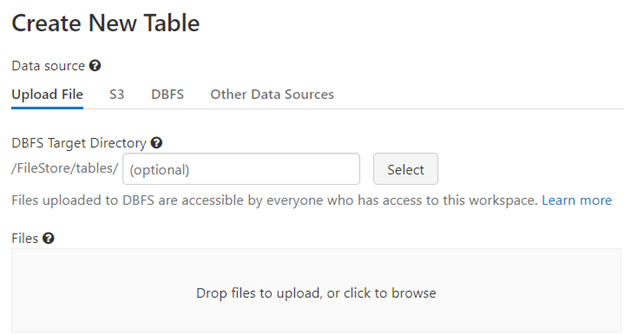
After the CSV file has been uploaded, click the 'Create Table with UI' button.

Click the 'Preview Table' button to see the table data (this will take a few seconds). Check the 'First row is header' box.
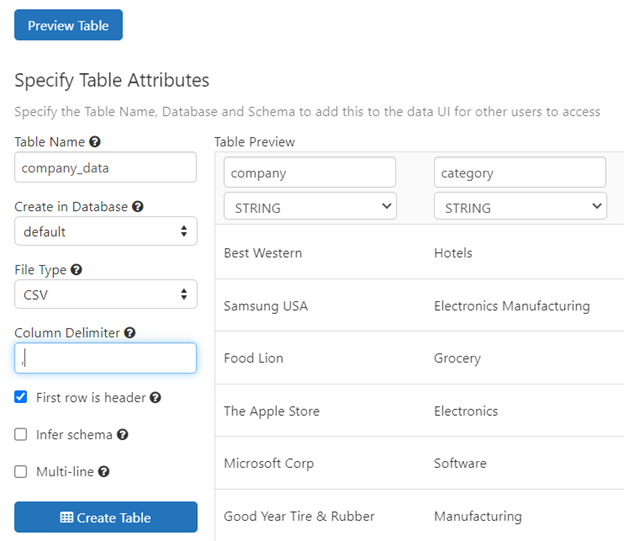
Click the 'Create Table' button. You will then see the schema and sample data.
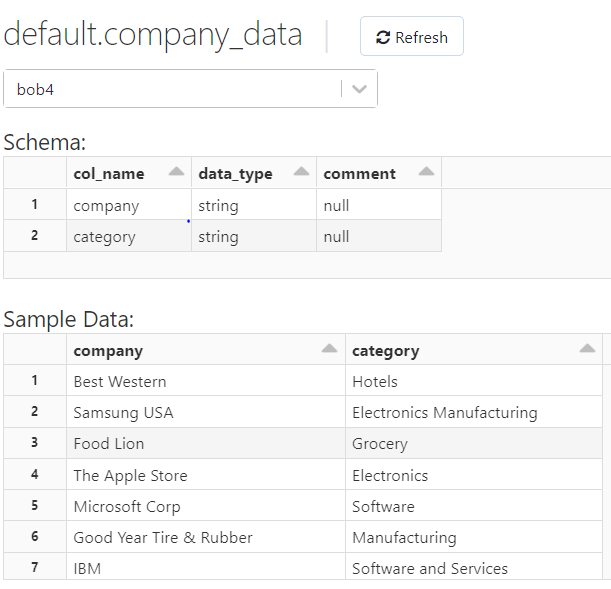
Step 8: Return to your Notebook. If you don't have the tab open, you can get to it from 'Recents' in the Databricks control bar. We will now the load the table data into a dataframe for processing. Don't forget [Shift]+[Enter] to execute the command in the Notebook.
# Load the table into a dataframe
df = spark.sql("select * from company_data")
Step 9: Since we will be using a User Defined Function (udf) we need to import the necessary libraries.
# Enable User Defined Functions (udf)
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
Step 10: We will now create the udf we will use from our earlier defined Python function.
# Create the udf from our Python function
match_udf = udf(match, StringType())
Step 11: Since dataframes are immutable, we will create a second dataframe that adds the additional column holding the similarity key for each company name record. The content of this column will be determined by our matching udf, which will in turn call the Interzoid Company Name Similarity Key API using the data content from the 'company' column.
# Generate similarity keys for the entire table by calling our user defined function
df_sims = df.withColumn("sim", match_udf(df["company"]))
Step 12: We will now show the contents of the new dataframe with the similarity keys. Note that it is this 'show' action that actually executes the processing.
# Show the results with the similarity key for each record in the new column
df_sims.show()
You can now see the new dataframe with the similarity keys column. You can see that similar company names share the same similarity key, such as 'Apple Inc.' and 'Apple Computer', or 'Ford Motors' and 'Ford INC.'. You can now do an 'order by', 'group by' or otherwise process this data to find the similar company names within them. This same concept can be used for data joins across multiple tables, using the similarity key as the basis of the SQL JOIN statement rather than the actual data itself to achieve much higher match rates.
You can now do the same of course with your own datasets, data files, and data tables.
Questions or further assistance? Please contact us at support@interzoid.com
AI Interactive Data Client: Request and Receive Structured Data of Any Kind on Any Subject.
More...
Github Code Examples
More...
Generate your own Datasets: Retrieve Customized, Real-World Data on Demand as Defined by You
More...
High-Performance Batch Processing: Call our APIs with Text Files as Input.
More...
Try our Pay-as-you-Go Option
More...
Available in the AWS Marketplace.
More...
Free Trial Usage Credits
Check out our full list of AI-powered APIs
More...
Documentation and Overview
More...
Product Newsletter
More...