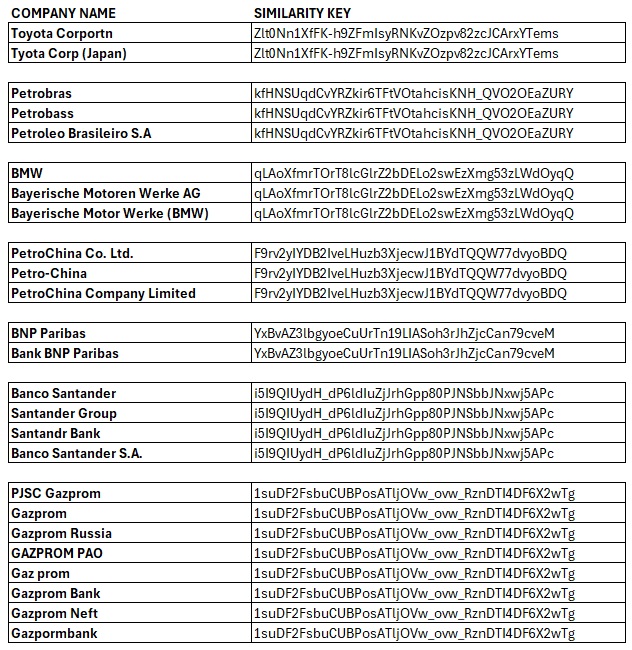
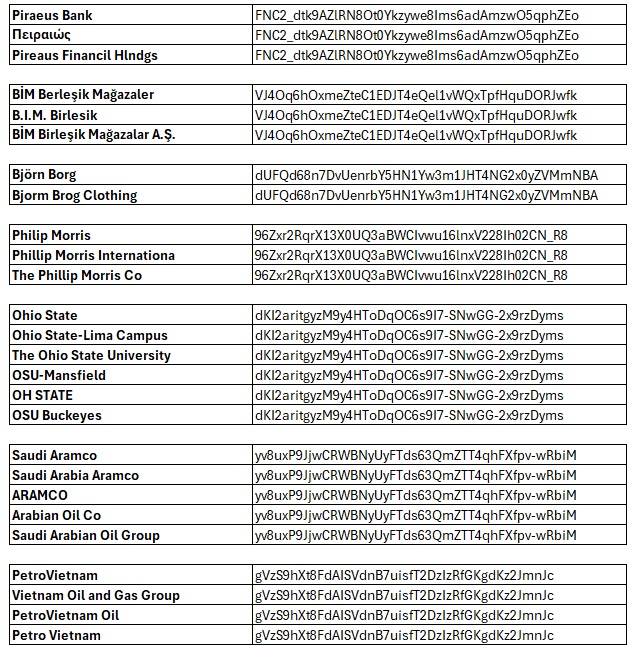
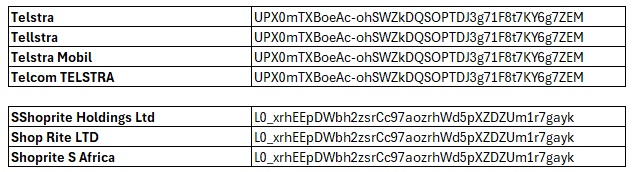
Why Is Dataset Matching Important?
Inconsistent data can lead to duplicate records, difficulties in aggregating data, inaccurate reporting, poor-decision making, and inefficiencies in business processes. Matching data across large datasets helps ensure that:
- Data remains clean: Prevents data duplication and inconsistencies, enables cross-dataset matching.
- Operations run smoothly: Data quality monitoring across workflows becomes automatic.
- Insights are accurate: Better data means better decision-making.
Interzoid’s Full Dataset Matching API delivers high-performance, automated matching processes to ensure your data is in top shape and prepared for seamless integration into your existing workflows.
Key Features and Capabilities
The API’s versatility makes it a must-have for any business dealing with large datasets. Here are some key features:
1. Automation
Leverage automation by scheduling data matching jobs directly into your ETL/ELT processes, workflows, or DevOps pipelines. Interzoid's API-driven approach lets you incorporate data quality monitoring into your day-to-day operations seamlessly.
Example: Automate nightly data quality checks by scheduling matching jobs to run at off-peak times, ensuring your systems remain efficient and free from inconsistencies.
2. Support for Multiple Data Sources
Interzoid's API supports various data formats, whether it's local files, cloud storage, or popular database platforms like Snowflake, PostgreSQL, MySQL, and more.
Example: A retail company can consolidate customer data from multiple sources—local CSV files, cloud databases, or enterprise SQL servers—into one cohesive dataset, identifying duplicated or inconsistent customer records.
3. Single Command/Query Simplicity
Run complex, high-performance matching operations with a single HTTP API request. This straightforward approach simplifies the integration of powerful data-matching algorithms into any system.
Example: With a simple API call, extract matching records from a CSV file of organization names and cluster them by similarity—all within seconds.
How the Matching API Works
Interzoid’s Full Dataset Matching API is simple to use but packs a powerful punch. You can initiate a matching job via a single API call using an HTTP request, which can be embedded into any process, batch file, or command line.
Here’s an example of how you can run a match report using a CSV data source:
Cut and paste into your browser URL address bar and hit 'return':
https://connect.interzoid.com/run?function=match&apikey=use-your-own-api-key-here&source=CSV&connection=https://dl.interzoid.com/csv/companies.csv&table=CSV&column=1&process=matchreport&category=company&html=trueThis call generates a match report that clusters inconsistent organization names from the first column of the CSV file, ensuring that duplicates are flagged and grouped together.
Example Use Cases:
- Company Name Matching: Compare, group, and match similar company names in a for organization-level analysis.
- Individual Name Matching: Detect duplicate customer records by matching individual names.
- Address Matching: Ensure that addresses are consistent across datasets, eliminating redundancy and enabling address-related analysis.
API Parameters Breakdown
To unlock the full potential of this API, you can customize the matching jobs using various parameters:
function=match: Specifies the matching function to be used.process=matchreport: Generates a report of matched data. You can optionally write out all records with their corresponding similarity key usingprocess=keysonly.source=CSV: Defines the data source format. Other options include SQL tables, Excel, and TSVs.apikey=your-api-key: Your Interzoid API key to authenticate the request.column=1: Specifies which column in a CSV file (in this example) to use for matching.
The API also supports additional parameters like json=true for returning results in
JSON format or html=true for more readable output in a browser.
See other available parameters here.
Seamless Integration with Cloud Databases
The API is fully compatible with cloud SQL data platforms like Snowflake, AWS RDS, Google Cloud SQL, and more. This enables easy integration for matching data stored in cloud database environments.
Example for Snowflake:
curl "https://connect.interzoid.com/run?function=match&apikey=use-your-own-api-key-here&source=snowflake&connection=username:password@account/database/schema&table=companies&column=company&category=company&process=matchreport"This call generates a match report for organization names in a Snowflake database, ensuring that duplicate records are clustered based on similarity and identified in real time.
Why Use This API?
The Full Dataset Matching API provides unmatched capabilities:
- Scalability: Handle large datasets effortlessly with high-performance parallel processing.
- Accuracy: AI-driven algorithms ensure precise matching results, including international data.
- Flexibility: Works across multiple data formats and platforms.
- Automation: Easily integrated into existing business processes and workflows. Match within a single dataset or across multiple datasets.
Take Your Data Quality to the Next Level
Interzoid’s Full Dataset Matching API empowers businesses to achieve superior data quality with very little effort. Whether you’re a small business or a large enterprise, this tool is designed to handle your data matching requirements and delivers value by keeping your data clean, consistent, and accurate.
Ready to supercharge your data quality? Explore the possibilities with Interzoid’s Full Dataset Matching API today!