Use our Latest AI Models for Best Matching Results with Global Individual Name Data
You can now call our Individual Name Matching API using our "AI-Plus" model with the name of an individual as a parameter for all worldwide data. A call to this Cloud API results in our AI models generating a hashed, canonical key string based on the name of the individual. The key is the same for all variations of the individual name. This key can be used to find similar records in the same dataset (simply sort the data by generated similarity key, like the matched similarity key clusters below). It can also be used to match data across datasets to get much higher match rates, such as in a data augmentation process.
| Sample API/URL Query: |
|---|
| https://api.interzoid.com/getfullnamematch?license=fh5hs7*****&fullname=John Smith |
| Sample JSON Output: |
|---|
| {"SimKey":"TIkSs6hraqimgfGatKakWh2OP_VaiKnJg8nGvROczI4","Code":"Success","Credits":365119} |
| Curl Example: |
|---|
| curl --header "x-api-key: fh5hs7*****" "https://api.interzoid.com/getfullnamematch?name=John Smith" |
Here are some example matching records that in this example have been matched/clustered because they share the same generated similarity key:
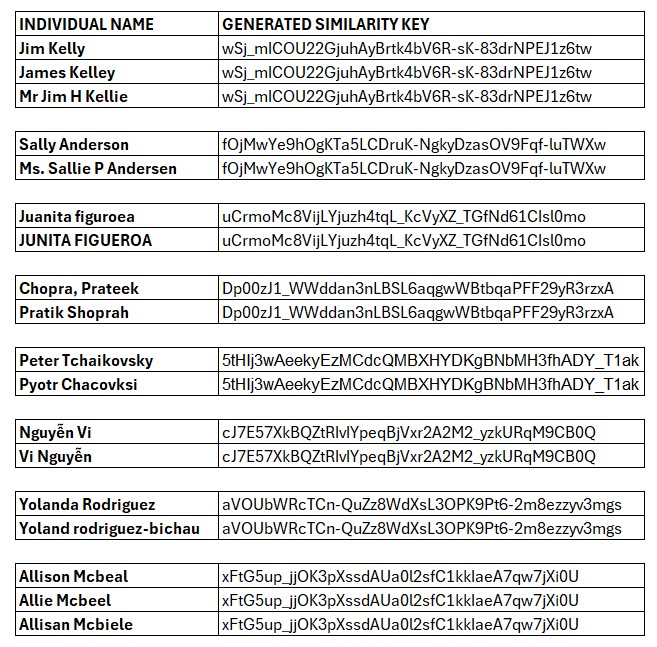
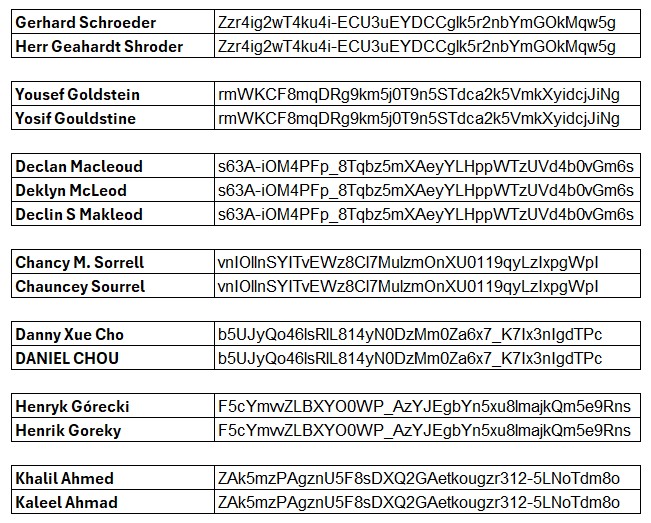
Using Interzoid's Cloud-native, AI-powered data quality and data matching capabilities, you can maintain accurate, standardized, and normalized individual name data, unlocking data-accelerated opportunities and driving significant business value from each of your high quality strategic data assets.
Try it out here.
Why is inconsistent name data an issue?
Having inconsistent individual name data present within your important data assets can lead to several problems in data-driven applications, processes and initiatives. Here are some examples.
Duplicate data and untrustworthy business intelligence:
When the same individual is collected and stored under multiple variations of their name, it leads to duplicate records of the same person within organizational data assets. This will skew analytics, reports, and dashboards, leading to incorrect insights and potentially flawed decision-making. For example, if a individual's purchases are split across multiple name variations, the true total sales figure for top customers may be underreported, causing lost opportunities for targeted marketing or resource allocation.
Significant difficulty in data integration and analysis:
Inconsistent naming conventions make it challenging to integrate data from different sources or systems. This can lead to time-consuming manual data cleansing and reconciliation efforts, increasing labor costs and delaying analysis and decision-making processes.
Lost opportunities for Customer Relationship Management (CRM):
When customer data is fragmented due to inconsistent corporate name data, it becomes difficult to gain a comprehensive view of a customer's interactions and history with your organization. This can result in missed opportunities for cross-selling, upselling, or providing personalized services, ultimately impacting customer satisfaction and revenue growth.
Compliance issues:
In some industries, inconsistent individual name data can lead to compliance and regulatory problems. For example, in financial services, failing to accurately identify and aggregate data related to a single person may result in non-compliance with anti-money laundering (AML) or know-your-customer (KYC) regulations, leading to potential fines and reputational damage.
Business process and operational inefficiencies:
Inconsistent individual names can cause operational inefficiencies in various business processes, such as invoicing, contract management, and vendor relations. These issues can lead to increased manual work, errors, and delays, resulting in higher operational costs, vendor overpayments, and potential missed opportunities for early payment discounts or favorable contract terms.
AI Interactive Data Client: Request and Receive Structured Data of Any Kind on Any Subject.
More...
Github Code Examples
More...
Generate your own Datasets: Retrieve Customized, Real-World Data on Demand as Defined by You
More...
High-Performance Batch Processing: Call our APIs with Text Files as Input.
More...
Try our Pay-as-you-Go Option
More...
Available in the AWS Marketplace.
More...
Free Trial Usage Credits
Check out our full list of AI-powered APIs
More...
Documentation and Overview
More...
Product Newsletter
More...