Many Solutions Begin with Matching Data
Posted on November 15th, 2022

One of the classic problems in computer science that stratifies vertical use cases is matching similar, yet inexact entities represented by electronic data.
For example, when comparing medical records across data sources, we would like to know that there is a very high chance that Robert Johnson and Rob Johnston with the same birthdate on the same street is indeed the same person.
In sales and marketing, we want to avoid the embarassment of contacting an existing customer with a "new customer opportunity" just because there is some variation in the spelling of a company name.
In Commercial Real Estate, we might want to identify instances of the same property owner even with name spelling variations in ownership records.
We might want to eliminate risk by matching names against known risk databases in various Financial Services scenarios that have been obtained from different sources of data and likely containing some data inconsistency.
In Analytics and Business Intelligence scenarios, we want to avoid the same company appearing as a customer multiple times due to spelling varations, or it can have serious consequences with decision making that is based on analysis of the data.
Regardless of the use case, there is a good chance overcoming inconsistency within datasets is an important part of the solution.
This is where we can help. The complexities involved in matching individual or company/organzation names can be considerably reduced by leveraging Interzoid technology and our similarity key capabilities.
Better data = better results.
Some examples:
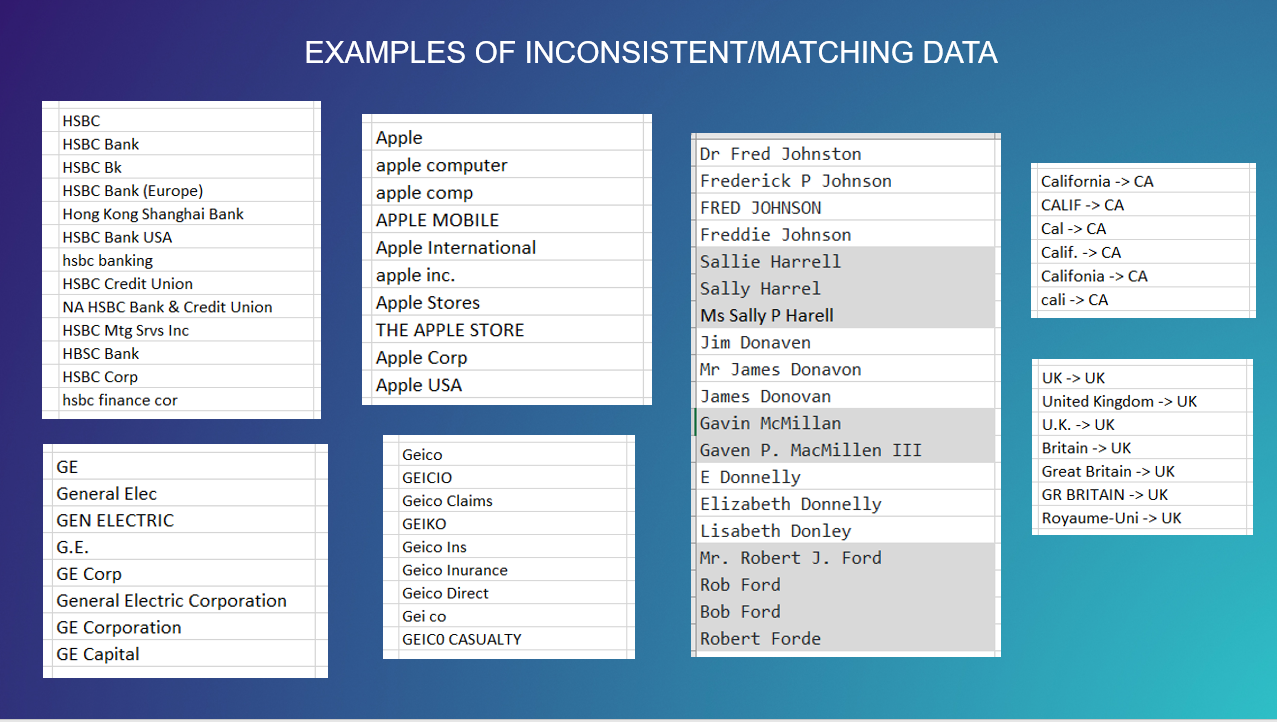
Learn more: Matching APIs
AI Interactive Data Client: Request and Receive Structured Data of Any Kind on Any Subject.
More...
Github Code Examples
More...
Generate your own Datasets: Retrieve Customized, Real-World Data on Demand as Defined by You
More...
High-Performance Batch Processing: Call our APIs with Text Files as Input.
More...
Try our Pay-as-you-Go Option
More...
Available in the AWS Marketplace.
More...
Free Trial Usage Credits
Check out our full list of AI-powered APIs
More...
Documentation and Overview
More...
Product Newsletter
More...