Matching and Merging Data Across Files using Similarity Keys
Posted on March 10th, 2020

Much value can be obtained from merging multiple files of data to get clearer, more comprehensive pictures of prospects, customers, and business opportunities. Data points that are spread across multiple sources are a classic example where the whole is greater than the sum of the parts, if only the data could be combined. Achieving this can unleash a large number of possibilities to use the newly merged data in all kinds of scenarios, including analytics, machine learning, and other forms of data analysis.
However, matching data across tables or merging files can be a challenge, especially if the only overlapping field is a textual field such as "company name", where the same data could be represented countless ways. Inconsistently-represented data, quite common, makes the ability match data using SQL queries or simple merge logic very difficult. Match rates will typically be very low. This stands in the way of aggregating data from multiple sources.
One technique that can make great headway in merging data sources is the use of API-generated similarity keys, where algorithms are used to eliminate data variance to generate a canonical key. The key is then used for matching rather than the actual data. This can increase match rates tremendously, making the desired data merge a reality.
For example, here is a snapshot case of matching two files where the only common field is a company name field:
Note the inconsistency in company name data, making it difficult to match and merge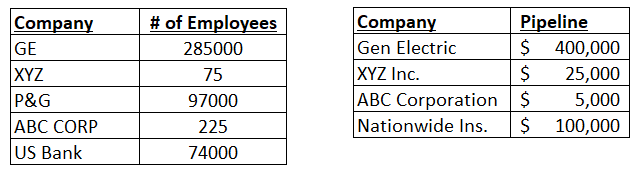
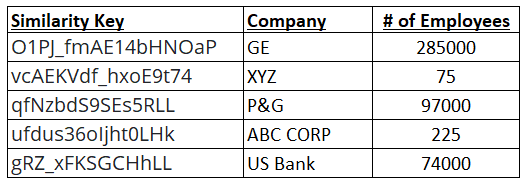
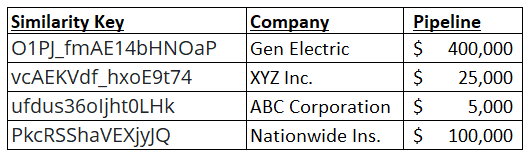
We can use each company name value to generate a similarity key by calling a Company Name Matching API for each record, where each request uses the company name string to generate the corresponding key. In this example, we will store the keys in the same table as a new column. Of course, they could be stored in separate tables with the use of a primary key to match similarity keys to company names.
We will use this similarity key as the basis for matching for our queries, rather than the actual company name content data. This will provide greater levels of matching.
In the output below, the merged file shows the combined data (similarity keys don't need to be included in the merged file of course).
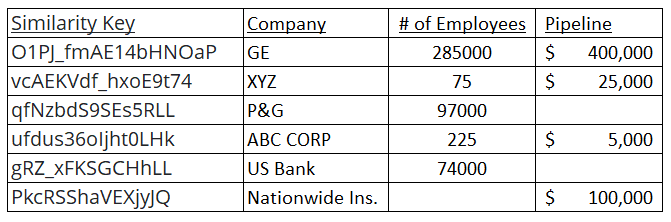
We now have a combined dataset as a result of being able to match across files with data that is inherently inconsistent in its representation.
AI Interactive Data Client: Request and Receive Structured Data of Any Kind on Any Subject.
More...
Github Code Examples
More...
Generate your own Datasets: Retrieve Customized, Real-World Data on Demand as Defined by You
More...
High-Performance Batch Processing: Call our APIs with Text Files as Input.
More...
Try our Pay-as-you-Go Option
More...
Available in the AWS Marketplace.
More...
Free Trial Usage Credits
Check out our full list of AI-powered APIs
More...
Documentation and Overview
More...
Product Newsletter
More...