How to Match Individual Name Data in Real-time using an API
Posted on September 25th, 2019

Name data can exist in many forms at the content level, making hard to match and analyze. This can substantially reduce the value and effectiveness of many data-oriented applications such as customer information systems, marketing systems, resource planning systems, accounting systems, and other business process-driven systems.
For example, "Bill Anderson", "William Andersen", and "Will P. Anderson" might all be the same person. The more other elements of a customer or prospect match, the more and more likely it is true. This inconsistency in name storage can cause difficulty in efforts to reduce data redundancy or when trying to pull data together from multiple systems for a specific purpose.
Also, having data spread across multiple customer or prospect accounts for the same individual can cause significant problems. These include embarrassment in the eyes of a customer regarding the management of account data, missed opportunities to grow the business, or can even result in various forms of conflict either internally or externally as multiple account executives reaching out to the same account.
Name representation inconsistency is just the beginning of data quality issues, as poorly structured data, incomplete data, and heterogeneous data stores add additional complexity and difficulty to these challenges.
The associated costs of redundant and inconsistent name data have been quantified. While it varies from company to company, it is estimated that on average, organizations lose millions of dollars in direct cost alone dealing with inconsistent and otherwise poor data quality. This leaves out the missed opportunities that correspond with the mastery of one’s organizational data assets. Long-term, indirect costs can be far greater too. Simple Web searches will return all sorts of cost analysis and horror stories associated with redundant and inconsistent business data, usually starting with individual names.
Interzoid addresses the problem by utilizing the concepts of similarity trees, smart hashing, and various forms of machine learning, including knowledge representation and reinforcement learning, to assist in the identity of inconsistent forms of name data that represent the same individual.
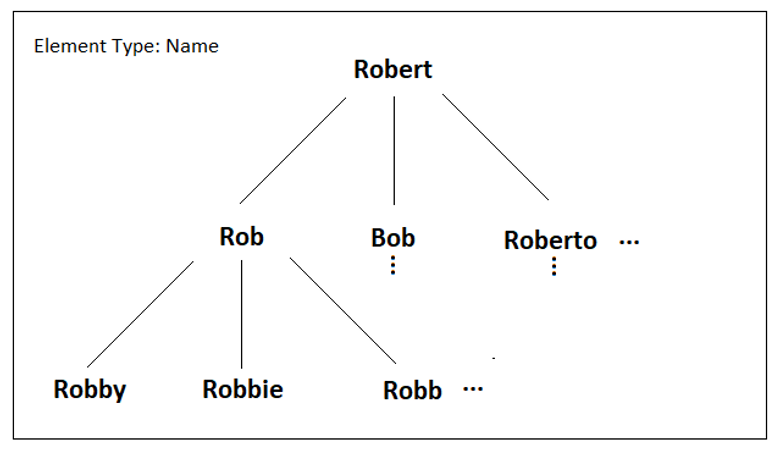
Based on its name data type, these similarity trees are quickly traversed in the Cloud using searching algorithms to find the location of a given name element such as “Robbie” and its unique leaf node location is used to generate the primary component of a smart hash, which in computer science is a value algorithmically computed from another, in this case for the purposes of accelerated data indexing.
Reinforcement learning techniques are utilized to help build existing trees and create new ones to improve the utility and accuracy of the entire system over time as its knowledge representation data structures grow.
Upon location of a similarity tree, the tree-based hashed smart value is then combined with other values using additional algorithms to create the actual similarity key that will be used for matching purposes. Variables such as data type, known common misspellings, reference databases, sound-alikes, and tree depth level searching variances can affect the generation of the similarity key.
The various Interzoid matching APIs that are used in this process have different endpoints based on content type of data (full name, city, company name, etc.) The type of data that governs the input parameters vary accordingly with each API call. Of course for name data, you will want to use the name data matching APIs. The API approach also enables an organization to start small and experiment, and then it can grow its use over time as success is achieved and a data matching strategy is in place instead of large capital asset software investments being used to try to address the issue.
To demonstrate how it works, the API is called with an input value as follows below. Upon completion of the appropriate algorithm, the generated similarity key is returned as an output parameter. This generated key can then be inserted into a database or dataset, or used on a temporary basis for matching data:

This process of retrieving a data value and calling the API is repeated for each data content element within the dataset that is being analyzed. Once complete, there are several ways the similarity keys can be used to identify data element permutations that likely represent the same individual.
The entire dataset can then be sorted by similarity key. This allows records that share the same similarity key to line up next to one another with the resultant sorted data. Alternatively, joins and filters can be used to identify matches in subsets of the dataset.
The similarity keys can be used for the purposes of matching during any kind of record search in real-time, rather than searching the actual name data itself, resulting in much higher rates when searching for matching records.
The results are most useful when multiple similarity keys are used as the basis of matching, as this dramatically reduces the number of false positives that are likely to occur if only utilizing similarity matching on one specific column:

Of course, other elements of data such as employer or birthday can help go even further in matching name identification. Use what's available within your data.
Once records are identified as likely matches, an organization’s business rules for treating as such take over to determine what must be done about the situation. In the case of simple mailing lists, high probability duplicates might be deleted. With redundant account records however, business-specific account-combining logic must be used if merging of records is desired.
For more information how Interzoid can help with your data matching strategy or to discuss how these issues are affecting your organization, please contact us at support@interzoid.com.
AI Interactive Data Client: Request and Receive Structured Data of Any Kind on Any Subject.
More...
Github Code Examples
More...
Generate your own Datasets: Retrieve Customized, Real-World Data on Demand as Defined by You
More...
High-Performance Batch Processing: Call our APIs with Text Files as Input.
More...
Try our Pay-as-you-Go Option
More...
Available in the AWS Marketplace.
More...
Free Trial Usage Credits
Check out our full list of AI-powered APIs
More...
Documentation and Overview
More...
Product Newsletter
More...