Using Multiple Algorithms to Improve Organization Name Matching
Posted on July 22nd, 2020
Are the data assets on which your company operate of questionable accuracy and efficiency? We have very little control over how customer, prospect, or other textual data is collected at its source. Therefore there is a good chance you are working within an organization where data quality could be significantly improved, thereby improving every process, activity, or analysis that makes use of this data.
There are many examples of data quality challenges for an organization to overcome. One is the difficulty of dealing with inconsistent company/organizational name data, such as the following:
IBM, International Business Machines, ibm, I.B.M.Forever 21, Forever Twenty-one, forever21
G.E., General Electric, Gen Electric
Johnson & More, Johnston and Moore Attys at Law
Apple, The Apple Store, Apple Corp USA
San Jose Memorial Hospital, Med Center of San Jose (Mem Hospital)
Inconsistent company/organization names like these in your databases can cause significant problems, such as:
- duplicate company records
- data and contacts spread across multiple records
- inaccurate data analysis
- difficult to match across data sources
- faulty-decision making
- increased data management costs
- inefficient business processes
- missed opportunities
Interzoid has created a similarity key generation capability that greatly simplifies and can even solve these challenging data issues.
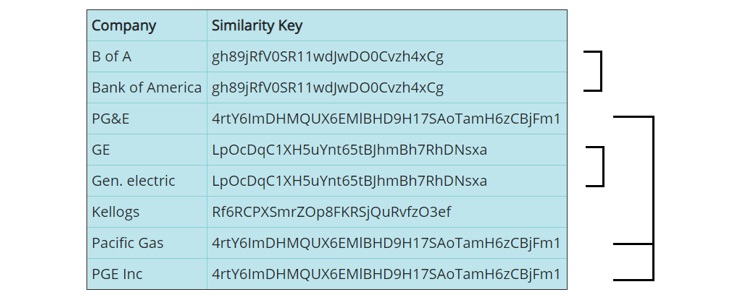
Our API generates a similarity key from a company name that is algorithmically designed to eliminate the inconsistency in the data content. Here are some examples of generated similarity keys:
We have recently added the ability to utilize different matching algorithms when generating similarity keys.
A "wide" key generation algorithm casts a wider net of possible matches for a given organizational name. The tradeoff
here is an increase in the possibility of false positive matches where organizational names are similar. The "narrow" algorithm
tightens the match requirements for two entities to generate the same similarity key. However, because of these tighter requirements,
some matches could be missed. Of course "medium" is somewhere in the middle. So depending on your organization's requirements and business case,
there are tradeoffs to consider.
Once similarity keys are generated for each organization in the target data source, data can be matched or sorted using these similarity keys rather than the data itself, resulting in dramatically higher match rates and identification of duplicate company names.
Using Interzoid's Company Name Match API, you can:
✔ Eliminate redundant and duplicate data from customer and important databases
✔ Leverage data content-specific matching algorithms for higher matching success rates
✔ Improve the accuracy of data analysis activities with better, more accurate foundational
data
✔ Be more cost-effective with customer communications and marketing campaigns
✔ Utilize fuzzy matching to match company data across datasets
✔ Enable fuzzy searching for better, more comprehensive search results
✔ Achieve greater ROI with business intelligence investments
✔ Leverage growing AI-based knowledge bases of matching and ambiguous data identification
✔ Reduce costs associated with redundant, duplicate data
✔ API-based solution enables full customization of data matching strategies
✔ Similarity keys easily are leveraged within a broad range of applications
✔ Easy to get up-and-running with immediate results
✔ Pay-as-you-go pricing makes it easy to get started
Sign up for an Interzoid account and you will receive automatic trial credits to take the API for a test drive.
Sample Matches Found Using Similarity Keys:
IBMInternational Business Machines
i.b.m. corp
U-Haul
Uhaul Trailers
Costco Stores
cost-co
McKeson Corp
Mackesson
The Mckesson company
Florida St
Florida State University
FSU
Well's Fargo Bank
Wells Fargo
Nationwide Insurance
Nation Wide Ins.
PFIZER INC
Fizer
Forever 21 Inc.
FOREVER TWENTY-ONE
Biogen Pharma
The Biogen Corp
Apple
apple computer
apple comp
APPLE MOBILE
Apple International
apple inc
apple inc.
Apple Stores
THE APPLE STORE
Apple Corp
Apple USA
7-11
7-eleven
Seven Eleven Stores
Seven 11 Inc.
Hilten Hotels
HiltonHotels
Hillton Resorts Inc.
Arctic Flooring Inc
Artic Floors
USX Corp
United Steel
Plain Dealer
Cleveland Plain Dealer
cleve Plain Dealer
Cleaveland Plane Dealer
Glaxo Smith Klein
GSK Pharmaceuticals
San Deigo Chemical
SD Chem
San Diego Chemical Corp
10k investments
Ten K Investment
Jackson Wines
Jaxon Winery Inc.
5 Penn Plaza Inc.
Five Pennsylvania Plaza
Cranston Inc.
The Cransten Corp
Cranstin Company
Hilton Hotels
Hillton Resorts Inc.
Perez Telecommunications Inc
peres telcom
Mary's Cookies
Marys Cookie Shop
High Top Brewing
Hightop Breweries
The Johnson Rehab Center
Johnsen Rehabilitation
JP Morgan
JP Morgan Chase
JPMorgan Chase
Midland Loan Services
Mid-land Savings & Loan
Midland Banking Svcs
Equity Real Estate Investments
$Equity Realtors
NBA
National Basketball Association
National Basketball Assoc. (NBA)
Saint Francis Mem (main)
St. Francis Memorial Hospital
AI Interactive Data Client: Request and Receive Structured Data of Any Kind on Any Subject.
More...
Github Code Examples
More...
Generate your own Datasets: Retrieve Customized, Real-World Data on Demand as Defined by You
More...
High-Performance Batch Processing: Call our APIs with Text Files as Input.
More...
Try our Pay-as-you-Go Option
More...
Available in the AWS Marketplace.
More...
Free Trial Usage Credits
Check out our full list of AI-powered APIs
More...
Documentation and Overview
More...
Product Newsletter
More...