Generating Company Match Reports in the Snowflake Data Cloud
Posted on January 26th, 2021

In this walkthrough example, Interzoid’s Cloud Data Connect Product is used to generate a “match report” using Interzoid’s Cloud-based Company Matching API, which in turn uses algorithmically generated “similarity keys.” These keys will serve as the basis of a match to identify similar company names within a database. This is a significant capability in improving the usability and accuracy of data that exists within Snowflake.
If you do not have access to Snowflake, a free trial is available at: https://signup.snowflake.com, which will work fine for this walkthrough.
You can access Interzoid's Cloud Data Connect here.
If you need more usage credits for your API license key for more testing, contact support@interzoid.com and mention this blog.
The premise of matching data is that Interzoid’s Company Matching API generates “similarity keys” based on matching algorithms, machine learning, and data-specific knowledge bases. These keys help identify similar company or organization names within a single database or across multiple data sources.
The use of these similarity keys helps to overcome the issues and challenges caused by inconsistent alphanumeric data for representing company names within a dataset. The technique can provide significantly greater impact and value for Cloud data warehousing efforts in making the resident data cleaner, more consistent, more usable, and therefore more valuable. It can also help identify data quality challenges in underlying source data that feed a data warehouse that need to be addressed.
It is important and useful not only to identify cases of redundant data records in a single dataset, but data matching via similarity keys can also significantly enhance the ability to match across multiple datasets where data can be inconsistently represented. The ability to get higher match rates when combining data from multiple sources to create new datasets or enhance existing ones can also add significant value.
For example, the following similarity keys were generated for the company names below.
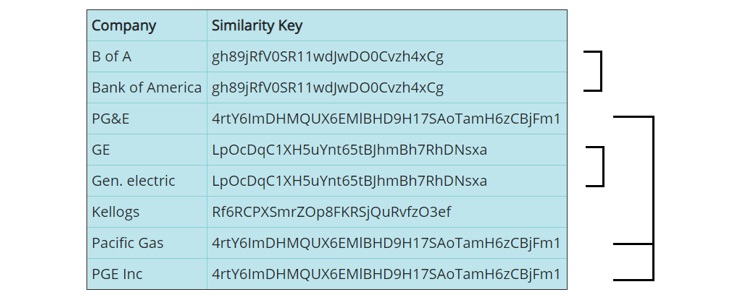
Using the Interzoid Company Matching API, likely matches will generate the same similarity key. You can see in the above example that similar company names generate the same similarity key. This makes them easy to identify as part of a data query.
How to connect to and create match reports within Snowflake:
There are four steps in this walkthrough:
Step #1: Load the sample data into Snowflake for this tutorial.
Step #2: Configure the data connection to Snowflake.
Step #3: Execute the match report.
Step #4: View the results.
Step #1 – Load the sample data into Snowflake
In this example, we will create a database within Snowflake and load a table from a simple CSV file. If you have not yet used Snowflake or do not have access to the Snowflake Cloud Data Warehouse, you can sign up for a free trial at: https://signup.snowflake.com
The sample CSV file we will use only has two columns, a company name and a description:

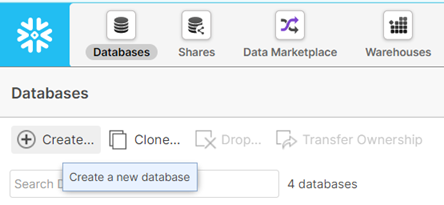
Log in to your Snowflake account. First, create a new database (click “Create…”):
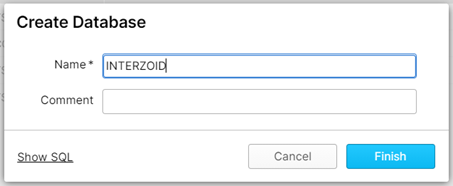
You can name the database whatever you want. However, for this tutorial, we will call it “INTERZOID”:
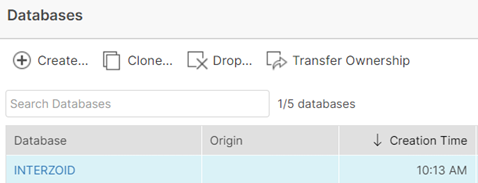
After you click “Finish”, then click on the newly created database from the list:
Now we will create a table for our data. From the Tables tab, click “Create” to create a new table:
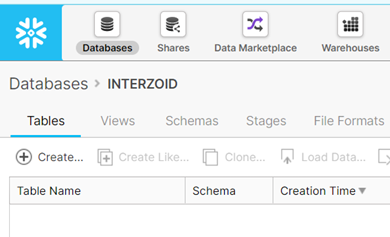
We will create a new table called “COMPANIES”, and create two columns within that table, “COMPANY” and “DESCRIPTION” of type “string.” This matches the CSV file we are going to load into the table.
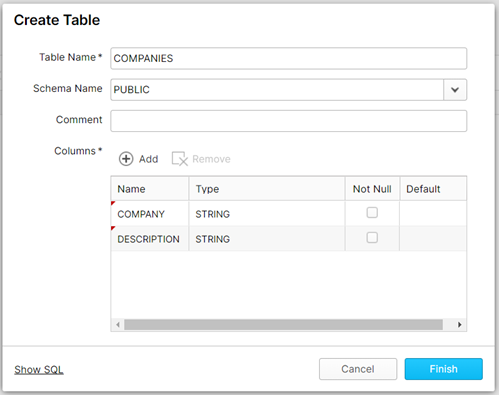
After the table is created, we will load the CSV file into the table. The default “COMPUTE_WH” warehouse is fine.
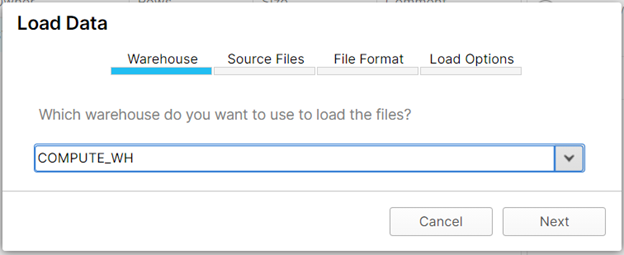
Next, browse to wherever you downloaded the CSV file via “Select Files…”
After you have selected your CSV file path, simply click the “Load” button.
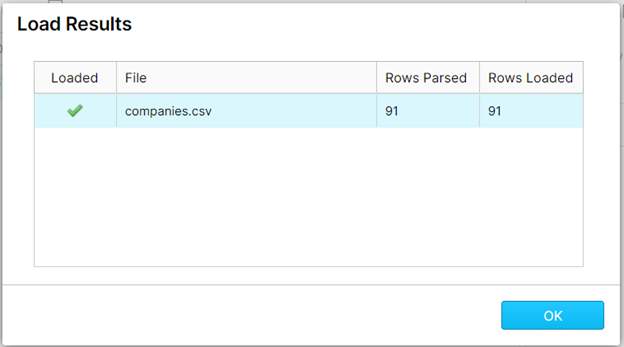
Once completed, your table loading results will be shown. Click “OK”.
Step #2 - Configure the data connection to Snowflake
We are now ready to create the data connection so Interzoid Data Connect can access the data within our Snowflake table via the Cloud. We will use an ODBC (Open DataBase Connectivity) connection to access the Snowflake data from outside the Snowflake Web application. To access the data, we will need a driver.
CData provides an ODBC driver for Snowflake. There is a free trial available you can download for this tutorial. This ODBC connector will enable us to read the Snowflake data via the Cloud: https://www.cdata.com/drivers/snowflake/odbc/.
Download and install this connector. There is a trial version available which will work fine for this tutorial.
One complete, open the Windows ODBC Administrator tool. The 64-bit version of the Odbcad32.exe file is located in the %systemdrive%\Windows\System32 folder. You can also search for it by typing “ODBC” in the Windows Start Menu Search box.
Click on the “User DSN” tab. Click “Add” to add a new data source.
Highlight the CData ODBC driver for Snowflake and then click “Finish.”
You will then see the CData ODBC Driver for Snowflake configuration panel. We will set this up for our Snowflake table that we will generate our match report against.
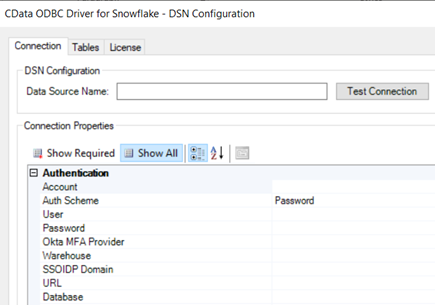
To use the CData driver, we need to configure it. We first need to create a data source name. Call it “mysnowflakeodbc”. Next, we will use the default Auth Scheme. Under “Authentication” enter your UserID and Password for Snowflake. This will allow the connection to the Snowflake Data Cloud at runtime.
We will also need to set the Warehouse name, which will likely be the default “COMPUTE_WH”. If not, use whatever name you used for the warehouse within Snowflake.
Next, set your unique Snowflake instance URL that you were provided with when you set up your Snowflake environment. You get can the URL from your Snowflake account. We also need to set the name of the database. We used “INTERZOID” when we set up the database within Snowflake, so use that for this parameter.
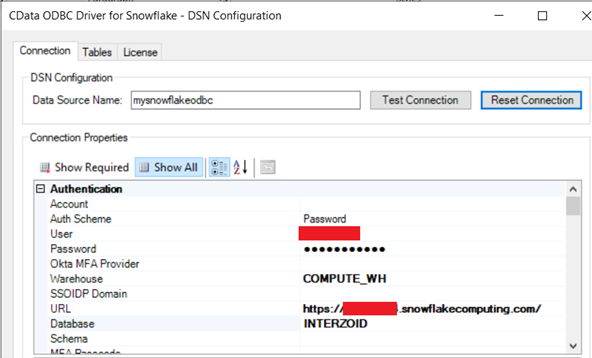
Here is the configuration panel when complete:
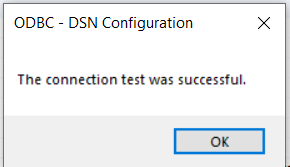
When ready, click the “Test Connection” button. You should see the following:
We are now ready to setup Interzoid Data Connect to generate the match report using the Interzoid Company Match API and the data within the selected Snowflake table.
Step #3 - Execute the match report
To support Windows, Linux, and Darwin, as well as multi-step data pipelines, Interzoid Data Connect runs from the command line. Contact Interzoid at support@interzoid.com for access to the product, and we will provide you with the necessary API usage credits to run the walkthrough. Once installed, you simply run it from a Windows, Linux, MacOS, or Solaris command prompt with the following parameters (see documentation for more details):
function – name of Interzoid API function to call
target – native, odbc, or textfile
dsn – ODBC connection name if using ODBC
license – your Interzoid API license key
algo – matching algorithm used with the Company Match API
table – database table name within Snowflake
column – name of table column in database to use as basis for match algorithms
To execute, from the command line, enter the following:
$ [C:/installdir] izdc -function=companymatch -target=odbc -dsn="DSN=cdatasnowflake" -license=[YOUR INTERZOID API KEY] -algo=wide -table=COMPANIES -column=COMPANY…and click [Enter]
Step #4: View the results
You can load the resultant output file into any viewing tool, such as Microsoft Excel or Notepad. You will see results like this, where sorted records that share the same Similarity Key are grouped together:
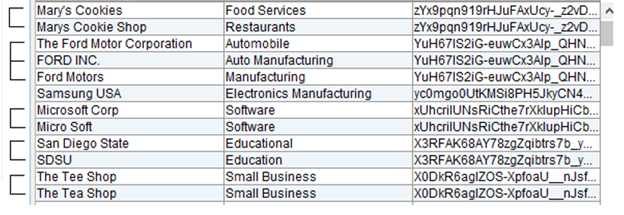
Where from here?
Now that matches have been identified, there are several potential courses of action to take, depending on business requirements.
For example, match report data can be imported into Snowflake for further analysis. Results can be saved/exported to a delimited file for review, importing to Snowflake, or for additional processing.
If this is a raw marketing list, redundant data could simply be eliminated to save outreach costs.
If this is a customer or prospect list, logic can be created to collapse redundant records into a single instance while maintaining important data from each of the records to maintain in the surviving record.
This walkthrough is only one example of integrating Interzoid APIs within Snowflake. There are also matching APIs that include specific matching algorithms for other types of data such as individual names (Bob = Robert, Johnson = Jonsen). There are data enrichment APIs available to add additional data elements via the Cloud to existing data that can enhance various data initiatives using Snowflake.
The possibilities are limitless.
For more information, contact support@interzoid.com or visit https://www.interzoid.com
AI Interactive Data Client: Request and Receive Structured Data of Any Kind on Any Subject.
More...
Github Code Examples
More...
Generate your own Datasets: Retrieve Customized, Real-World Data on Demand as Defined by You
More...
High-Performance Batch Processing: Call our APIs with Text Files as Input.
More...
Try our Pay-as-you-Go Option
More...
Available in the AWS Marketplace.
More...
Free Trial Usage Credits
Check out our full list of AI-powered APIs
More...
Documentation and Overview
More...
Product Newsletter
More...