Understanding Interzoid's AI-Powered Data Matching

Leverage emerging Generative AI capabilities to solve these issues
Electronic data usually originates from a variety of sources and is collected using multiple methods. Consequently, this data can take on many forms and frequently displays considerable inconsistency. Such irregularities in electronic text data representation and storage can notably diminish the performance, effectiveness, and value of numerous data-centric applications, including Analytics, Business Intelligence, Data Science, CRM, Call Centers, Marketing systems, Artificial Intelligence, and Machine Learning.
For example, the following are all ways the same elements of data can be represented in a database:

Often, these data inconsistencies result in multiple versions of the same entity existing within a dataset. This in turn can cause significant inaccuracies during data reporting activities such as analyzing a customer base or reporting numerically by data entity. Inconsistently represented data across tables or databases can make matching data across these datasets difficult and performing analysis nearly impossible.
Redundant data can not only have a negative effect on Analytics, it can cause significant problems operationally. These include embarrassment in the eyes of a customer regarding the management of account data, missed opportunities to grow the business, or can even result in various forms of conflict either internally or externally as multiple account executives reach out to the same customer account.
Top analyst firms frequently quantify the costs of poor data quality usually running at more than a $15 million USD annual cost on average per organization. This is substantial. Data redundancy and data inconsistency is often a major challenge that drives this figure. As more and more data is now moving to the Cloud and becomes more accessible across an organization, and to customers, partners, and prospective customers, resolving these issues is critical.
How does Interzoid address this?
Interzoid uses an AI-centric algorithmic approach to identify instances of data inconsistency in various data sources with the creation of a "Similarity Key". Similarity Keys are hashes of data that are formulated using several methods, including Generative AI that leverages Large Language Models (LLMs), knowledge bases, various heuristics, sound-alikes, spelling analysis, data classification, pattern matching, and utilizing multiple approaches to Contextual Machine Learning. The concept is that data that is "similar" will algorithmically generate the same hash, or what we call a Similarity Key. The key can then be used to identify and/or cluster data that is similar.
For example, generated Similarity Keys for company/organization names:
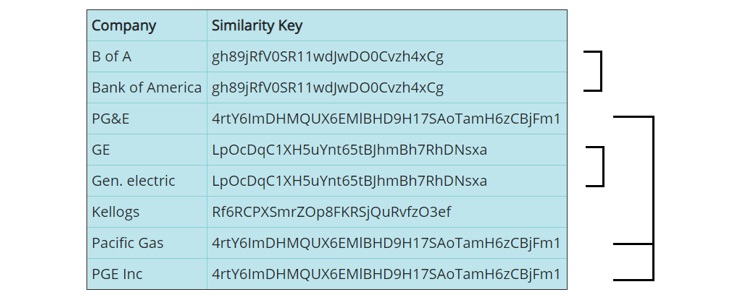
At the very core level, we use an AI-powered API to provide access to our servers that generate these algorithmic Similarity Keys. A raw data value is simply passed to the API, and the Similarity Key is returned after traversing several different layers of analysis. It can then be used to compare with Similarity Keys generated by other raw data values. Data from an entire dataset can be passed through an API to generate Similarity Keys for each and every record, including multiple columns and multiple data types. Once processing is complete, there are several ways the Similarity Keys can be used to identify data element permutations that likely represent the same piece of information.
For example, an entire dataset can be sorted by Similarity Key. This allows records that share the same Similarity Key to line up next to one another within the sorted data, identifying match candidates. In addition, views, joins, and other data filters can be used to identify matches within subsets of a dataset or used to search for records that are similar within a dataset (sometimes known as "fuzzy searching"). The Similarity Keys can also be used as the basis of a match across datasets, resulting in much higher match rates than what could be achieved via straight textual matching.
The results are most useful when multiple Similarity Keys, generated on more than one data type, are used as the basis of matching, as this dramatically reduces the number of false positives that are likely to occur if only utilizing similarity matching on one specific column:

Once records are identified as likely matches, an organization’s business rules for treating them as such take over to determine what must be done for resolution. For example, in the case of simple mailing lists, high probability duplicates might be deleted. With redundant customer account records however, business-specific account-combining logic must be used if merging of records is desired to capture data from the multiple versions of the same data element. In an ELT scenario as part of a data warehouse, Similarity Keys can be appended to an existing table or stored in a new table. Once the Similarity Keys are available within a collection of data for joins, queries, and analysis, the possibilities for use and value are infinite.
Additional Links:
Interactive Matching from the Browser
Quick and Easy Interactive Matching Tutorial
APIs to Analyze and Match Entire Datasets
Ready to get started with free usage credits? Register here
to obtain your license key.
For more information as to how Interzoid can help with your data matching strategy or to discuss how
these
issues are affecting your organization, please contact us at support@interzoid.com.
AI Interactive Data Client: Request and Receive Structured Data of Any Kind on Any Subject.
More...
Github Code Examples
More...
Generate your own Datasets: Retrieve Customized, Real-World Data on Demand as Defined by You
More...
High-Performance Batch Processing: Call our APIs with Text Files as Input.
More...
Try our Pay-as-you-Go Option
More...
Available in the AWS Marketplace.
More...
Free Trial Usage Credits
Check out our full list of AI-powered APIs
More...
Documentation and Overview
More...
Product Newsletter
More...