Matching Data in Snowflake: Three Ways

A requirement of finding duplicates, fuzzy matching, eliminating redundancy, and identifying data inconsistency are all ways of saying that you have some data that needs to be cleaned, wrangled, prepared, and otherwise organized before its value can be maximized.
If these requirements are not met, then it can substantially compromise efforts at Analytics, Reporting, Data Science, AI/ML, CRM, Marketing, or other data-driven initiatives that depend on accurate, consistent data for successful outcomes.
Here are some samples of different types of inconsistent, matching data:
G.E.
Gen Electric
General Electric
Bill Jameson
William R. Jamison
500 Browne lane suite #100
500 Browne ln suite 100
500 brown lane ste 100
Here are three ways you can address this issue quickly and easily and on the fly with Interzoid and your Snowflake data.
#1) Generate a match report.
This will analyze an entire table of data (or view) and auto-generate a data match report to see how significant of an inconsistent/duplicate data challenge you have.
This can be achieved executing the following single command from the command line (it's an API call utilizing cURL). All you need is your Snowflake connection string, table name, and column name. You also need to indicate which set of matching algorithms to use based on the data content type (company/organization names, individual names, or street addresses).
curl 'https://connect.interzoid.com/run?function=match&apikey=use-your-own-api-key-here&source=Snowflake&connection=your-specific-connection-string&table=companydata&column=companynames&category=company'
(Note: remember that within Windows, cURL requires double rather than single quotes.)
You will need to register with Interzoid to get an API key to include as a parameter with a subscription plan in place.
Example: Snowflake data table.
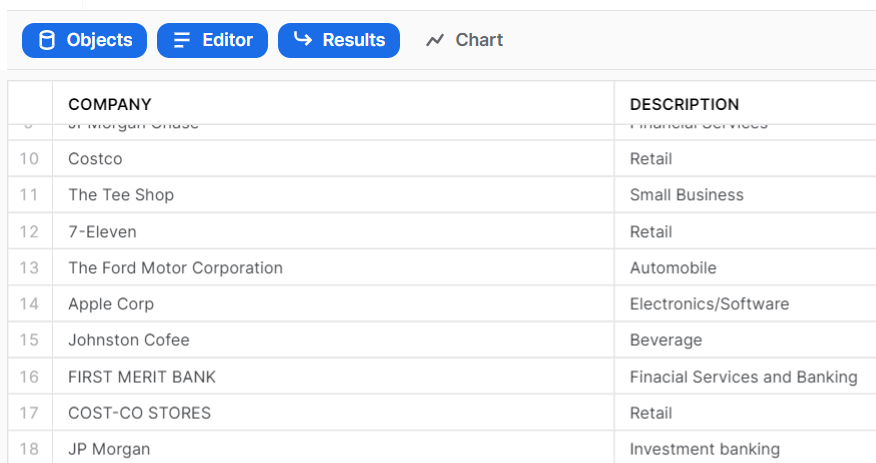
Using the command-line approach is useful because it enables match reports to be generated as scheduled and
at desired time intervals, as part of a batch script, within a data pipeline, embedded as part of a business process,
within an ELT/ETL process, or whichever else makes sense for a given business scenario.
For example, the console output of the match report can be redirected into a .CSV file and then loaded into Excel:

If you want to achieve the same results interactively from the browser, you can do so by using our interactive Web application to do so:
There is a quick tutorial on how to do so here.
When the match report is generated, the system will analyze each of the values in the selected data column. It will apply various matching algorithms including Contextual Machine Learning, utilization of knowledge bases, heuristics, spelling analysis, soundalikes, and more. When finished, a report will be generated and "matching clusters" can be viewed. If using the command-line approach, as in the above example, the output can be redirected to a file to be used and/or viewed as desired.
#2) Create a new table in Snowflake with Similarity Keys attached.
Sometimes matching can occur within single tables to identify inconsistent and otherwise redundant data. The use of "Similarity Keys" can aid significantly in the process.
A Similarity Key is essentially a hashed value that links together match clusters. Column values that are determined to be a match using Interzoid matching algorithms will share the same Similarity Key. This can be within a given data table, but it also works across multiple tables. In this case, Interzoid will analyze all of the values of the selected column, and then create a new table within Snowflake containing the selected values along with their corresponding Similarity Keys (another reference column can be included as well, such as a foreign key to the source table).
This allows Interzoid's Similarity Keys to be leveraged with custom logic to match data within a single table, or to perform joins using the Similarity Key as the basis for the matching data, allowing for much higher match rates when matching data across tables.
The creation of a new table within Snowflake to store Similarity Keys can be achieved by executing a command similar to the one in #1 above, however with some different parameters:
curl 'https://connect.interzoid.com/run?function=match&apikey=use-your-own-api-key-here&source=Snowflake&connection=your-specific-connection-string&table=companydata&column=companynames&process=createtable&newtable=companysimkeys&category=company'
The newly auto-created table within Snowflake is below. Note that two permutations of "Costco" generate the same Similarity Key. This would be true as well if the variations of the Costco name happened to be in two separate tables.
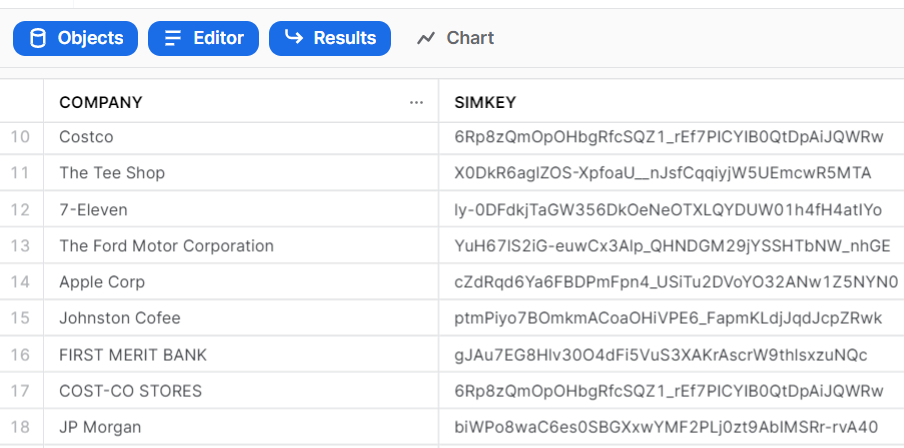
Again, the command-line approach is useful because it enables this kind of report to be generated as scheduled and at desired time intervals, as part of a batch script, within a data pipeline, embedded as part of a business process, within an ELT/ETL process, or whichever else makes sense for a given business scenario.
Here you can also achieve the same result interactively by using our interactive Web application to do so (see tutorial link above):
In addition, this same Similarity Key generation process can be instructed to generate a text file with Similarity Keys attached by using the command in #1 above with the additional parameter of "&process=keysonly".
#3) Generate a SQL Insert script to load into Snowflake.
Generating an Insert script is an option if a data source is located outside of Snowflake, within another instance of Snowflake, or if the script is the preferred approach for loading data into Snowflake with Similarity Keys.
Here is the command for doing so:
curl 'https://connect.interzoid.com/run?function=match&apikey=use-your-own-api-key-here&source=Snowflake&connection=your-specific-connection-string&table=companydata&column=companynames&process=gensql&category=company'
The output is simply a series of Insert SQL statements where you can find-and-replace the desired table name, as well as redirect this output to a file. In the example below, note that variations of "JP Morgan" & "Costco" generate the same similarity key:
INSERT into YOUR_TABLE (company,simkey) VALUES ('IBM','edplDLsBWcH9Sa7ZECaJx8KiEl5lvMWAa6ackCA4azs');
INSERT into YOUR_TABLE (company,simkey) VALUES ('Hillton Resorts Inc.','bYJkyBAaMbvxkPMDf74Mul-LfR3jO8LxDyRvS-B-_k8');
INSERT into YOUR_TABLE (company,simkey) VALUES ('JPMorgan Chase','biWPo8waC6es0SBGXxwYMF2PLj0zt9AbIMSRr-rvA40');
INSERT into YOUR_TABLE (company,simkey) VALUES ('Costco','6Rp8zQmOpOHbgRfcSQZ1_rEf7PICYIB0QtDpAiJQWRw');
INSERT into YOUR_TABLE (company,simkey) VALUES ('The Tee Shop','X0DkR6aglZOS-XpfoaU__nJsfCqqiyjW5UEmcwR5MTA');
INSERT into YOUR_TABLE (company,simkey) VALUES ('7-Eleven','ly-0DFdkjTaGW356DkOeNeOTXLQYDUW01h4fH4atIYo');
INSERT into YOUR_TABLE (company,simkey) VALUES ('The Ford Motor Corporation','YuH67lS2iG-euwCx3Alp_QHNDGM29jYSSHTbNW_nhGE');
INSERT into YOUR_TABLE (company,simkey) VALUES ('Apple Corp','cZdRqd6Ya6FBDPmFpn4_USiTu2DVoYO32ANw1Z5NYN0');
INSERT into YOUR_TABLE (company,simkey) VALUES ('Johnston Cofee','ptmPiyo7BOmkmACoaOHiVPE6_FapmKLdjJqdJcpZRwk');
INSERT into YOUR_TABLE (company,simkey) VALUES ('FIRST MERIT BANK','gJAu7EG8Hlv30O4dFi5VuS3XAKrAscrW9thlsxzuNQc');
INSERT into YOUR_TABLE (company,simkey) VALUES ('COST-CO STORES','6Rp8zQmOpOHbgRfcSQZ1_rEf7PICYIB0QtDpAiJQWRw');
INSERT into YOUR_TABLE (company,simkey) VALUES ('JP Morgan','biWPo8waC6es0SBGXxwYMF2PLj0zt9AbIMSRr-rvA40');
Each of these scenarios can go a long way in significantly improving the quality and accuracy of data both prior to and as the data is being put to use. This will result in better outcomes with the data-driven use cases that depend upon this data.
AI Interactive Data Client: Request and Receive Structured Data of Any Kind on Any Subject.
More...
Github Code Examples
More...
Generate your own Datasets: Retrieve Customized, Real-World Data on Demand as Defined by You
More...
High-Performance Batch Processing: Call our APIs with Text Files as Input.
More...
Try our Pay-as-you-Go Option
More...
Available in the AWS Marketplace.
More...
Free Trial Usage Credits
Check out our full list of AI-powered APIs
More...
Documentation and Overview
More...
Product Newsletter
More...