Data Virtualization, Interzoid’s Company Data Matching API, and Denodo: Find Redundant Company Names Within a Data Source, Step-by-Step
Posted on September 22nd, 2020
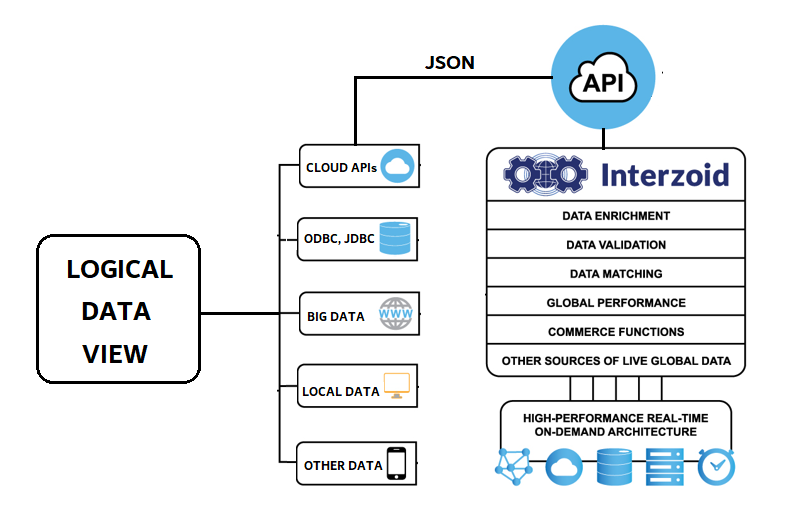
This is Part One of a two-part series showing the power of using APIs with data virtualization solutions.
Data Virtualization enables disparate data sources across an organization to be viewed and made accessible within a single logical data layer. This allows aggregated data to be delivered to business users in real-time, as well as provides the foundation for data warehouses, data lakes, and other analytics sources.
In this walkthrough example, Denodo is used to perform a Join on a virtual database with Interzoid’s Cloud-based Company Matching API using algorithmically generated “similarity keys.” These keys will serve as the basis of a match to identify similar and inconsistently-represented company names within a database. This essentially turns Denodo into a powerful data matching tool.
If you do not have Denodo, a limited-version called Denodo Express is available as a free download here and will work with this walkthrough.
The premise of matching data is that Interzoid’s Company Matching JSON-based API generates “similarity keys” using algorithms, machine learning, and data-specific knowledge bases. These keys help identify similar company or organization names within a single database or across multiple databases as part of an SQL Join (or other similar data matching) function.
The use of similarity keys helps to overcome the issue of inconsistent alphanumeric data for representing company names within a dataset. The technique can provide significantly greater impact and value for Data Virtualization efforts and the various data initiatives that make use of a logical data layer. It can also help identify data quality challenges in underlying source data that need to be addressed.
It is important and useful not only to identify cases of redundant data records in a single dataset, but data matching via similarity keys can also significantly enhance the ability to match and join data across multiple datasets where data can be inconsistently represented. This increases the accuracy and value of data residing within the Data Virtualization layer.
For example, the following similarity keys were generated for the company names below.

Using the Interzoid Company Matching API, likely matches will generate the same similarity key. You can see that similar company names generate the same similarity key. This makes them easy to identify as part of a data query.
How to achieve matching results with Denodo using data virtualization:
There are five steps in this example:
Step #1: Create a Data Source and Base View within Denodo for the source data
Step #2: Configure the Interzoid Company Matching API as a Data Source
Step #3: Configure the Interzoid API Base View
Step #4: Define the Derived View using a Join function
Step #5: Execute the Join function to display results
Step #1 – Create a Data Source and Base View within Denodo for the source data
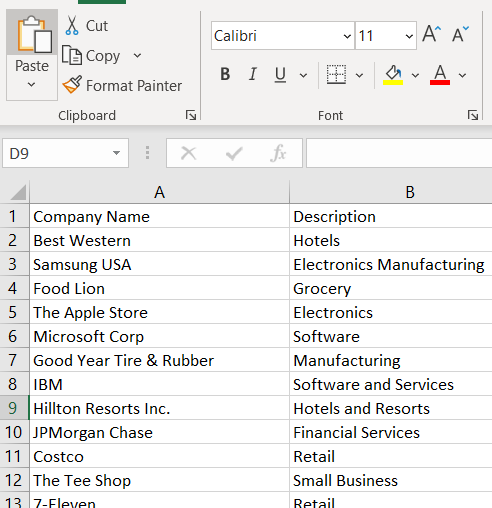
In this example, for simplicity we will use an Excel workbook file as the data source (we could have just as easily used JDBC, ODBC, or one of the several other data sources available within Denodo). It is a list of company names with a simple description. Filename: “Example 1 – Companies.xlsx”
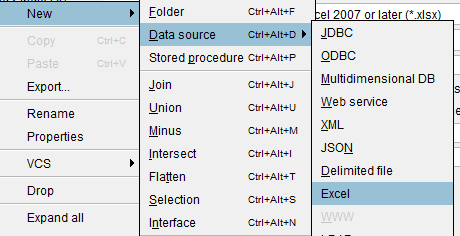
Within the Virtual DataPort Administration Tool (VDP) of Denodo, select “Database Administration” and create a new Server for this walkthrough. Call it “Example1.” Then, from the “Example1” folder in the Server tree, create a new folder called “Data Sources” and another one called “Base Views.” Within the “Data Sources” folder, create a new Excel Data Source.
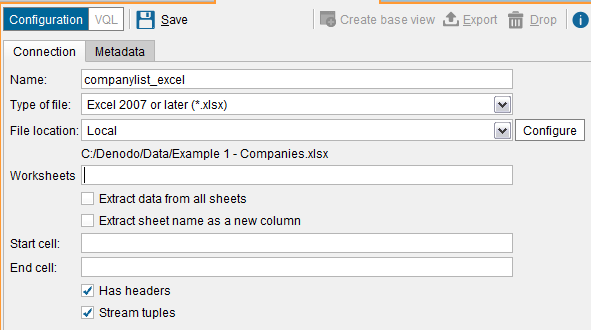
Next, change the File Location setting to “Local” and click the “Configure” button. Provide the path of the included Excel file and click “Ok.” Name the Data Source “companylist_excel”. Check the “has headers” option and click “Save”:
Next, click “Create base view” on the top. Once the Base View has been created and is displayed, click “Save”
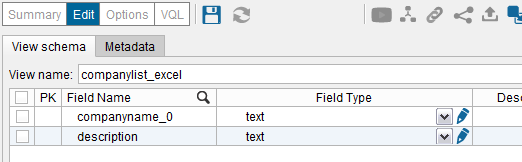
You should now have both a Data Source and the corresponding Base View in your Server tree (you might need to drag the Base View to the Base View folder):
Step #2 – Configure the Interzoid Company Matching API as a Data Source
The API we will use is a REST based API that we will access using query parameters with a URL location. Data is returned from this API in JSON format, so we will set the data source up in Denodo accordingly.
For more technical information about the API:
https://www.interzoid.com/apis/company-name-matching
Create a new data source of type “JSON”
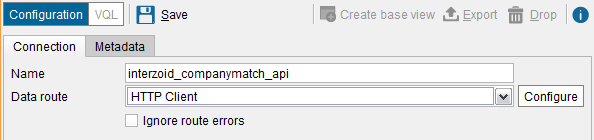
Name the data source: “interzoid_companymatch_api”
For the “Data Route”, choose “HTTP Client” and then click the “Configure” button:
The end point for this particular API is:
https://api.interzoid.com/getcompanymatchadvanced
Calling the API requires three parameters:
License: A license key issued from Interzoid (a limited key is provided for this example, additional license keys can be obtained from Interzoid)
Company: Company name from which similarity key will be generated
Algorithm: Which similarity key generation algorithm will be applied
In this example, we will hard-code values for two of the parameters in the call, “license” and “algorithm.” For the third parameter, “company name”, we will use an “interpolated value”, as this tells Denodo to use a variable when calling the API. In our case, the variable will be company name values from the company list Base View that we have already set up from the source data in the Excel file.
To achieve this, in the URL field when configuring the HTTP client, we will provide the endpoint along with the query parameters. You can see the two hard-coded values for “license” and “algorithm”, and then also how the interpolated variable is denoted within the API call URL using an @ symbol and brackets:
(Note: if you don't have a license key, register at https://www.interzoid.com/register)
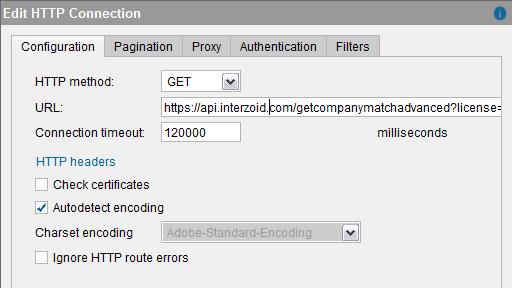
Click “OK”, and then “Save.” The configured Data Source will appear on the Server tree:

Step #3 – Configure the Interzoid API Base View
On the Configuration Panel for the “Interzoid_companymatch_api” Data Source, click “Create Base View.” You will see the following:
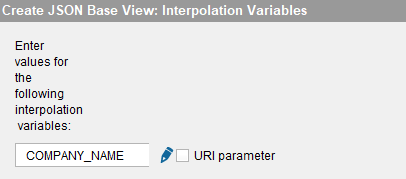
Click the blue edit pen and then enter the interpolation variable notation below including the brackets:
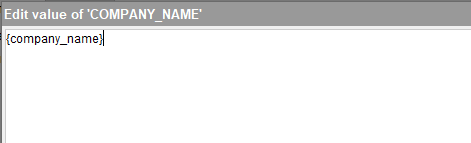
Then click “OK”, then “Next”, and then “OK” again at the “Configure JSON Wrapper” panel without any changes.
You should then see the following:
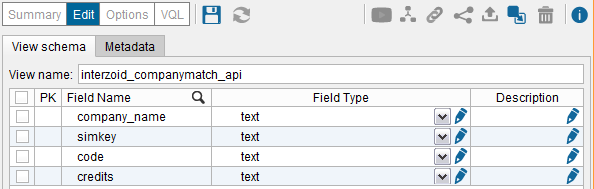
The “company_name” field is the input parameter to the API. The other three are all output parameters that will comprise the output results. All four data fields are listed here. Click the blue “Save” disk to save the Base View.
You should now have the new Base View available on the Server tree as shown:
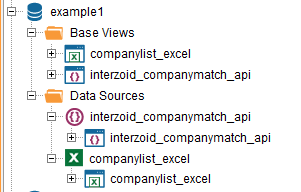
Step #4 – Create the Derived View using a Join function
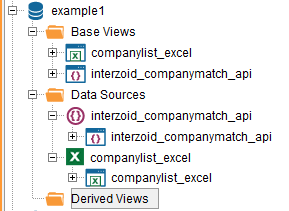
Create a new folder called “Derived Views” to follow Denodo guidelines. This is where the Data Virtualization will occur and from where we can execute our Join function. This will call the API with each value in the company list data source generating similarity keys for each and storing them within a Derived View.
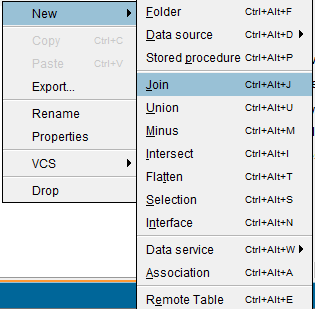
In this folder, create a new Join function:
Then, drag the two Base Views from the tree onto the Join configuration panel. The panel should look like this:
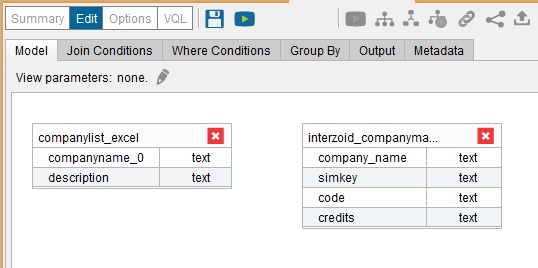
Next, drag the “companyname_0” field of the company list Base View to the “company_name” field of the Interzoid API Base View. You should see a line connecting the two fields (defining the Join) like this:
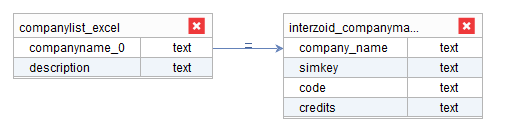
Next, define the output of the Derived View. Click the “output” tab. Then, check the three fields as shown below.
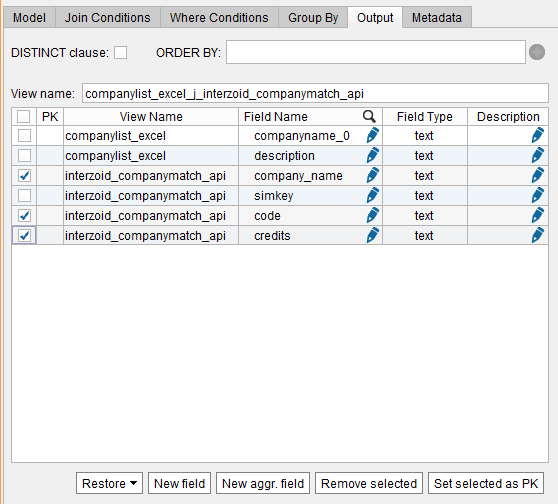
The first field selected is the input parameter to the API. This will be the same as the company name field in the Excel worksheet, so we do not need to see it twice. Also, “code” and “credits” are administrative data coming from the API that are not relevant to the Join, so check those as well. After the fields are checked, click the “Remove selected” button the bottom of the panel. You should now see this:
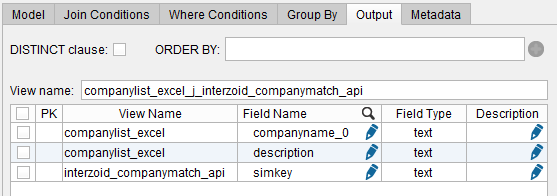
Click the blue disk “Save” button. The Join function’s Derived View will now appear in the Derived Views folder on the Server tree:
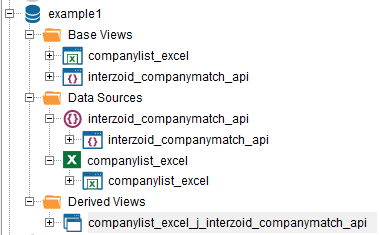
Step #5 – Execute the Join function to display results
Within the configuration panel for the Derived View, click the “Execution Panel” arrow at the top. You should see the following:
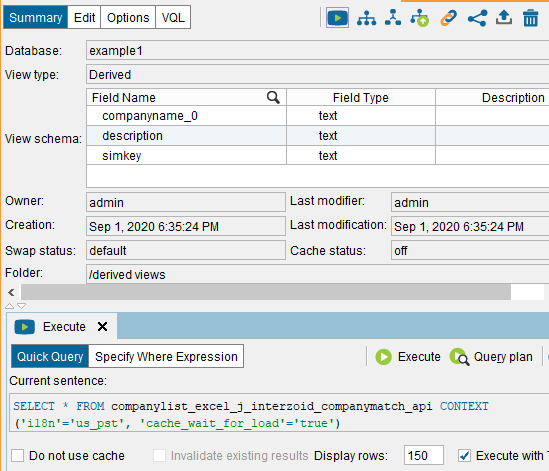
We are ready to execute the Join function that will build the Derived View by calling the API once for each record in the company list Base View. To execute, click the white arrow in the green circle “Execute” button.
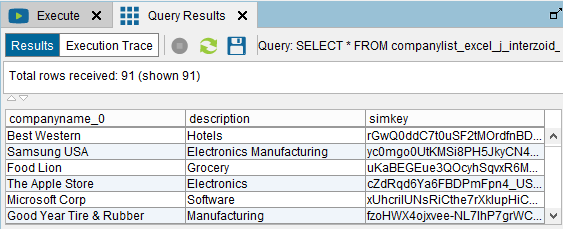
You should see the “Executing query…” message. This will take a few seconds as Denodo is going to the Web to execute the Interzoid Company Matching API for the purposes of generating similarity keys.

You will then see the results as shown. For each company name, you will see a generated similarity key (“simkey”: a string of alphanumeric characters):
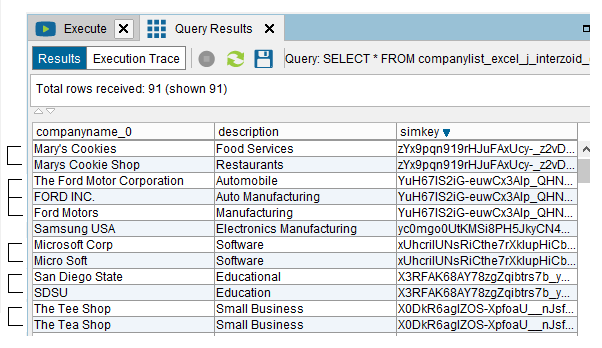
The next thing we want to do is to sort the data by “simkey” (this can also be done by adding an “order by” clause to the SQL query prior to execution of the query). To do this within the query results, click the “simkey” column header twice to sort in descending order. Sorting by “simkey” will cause similar company names to line up next to each other. This makes the potential matches easy to find. You should see something like the following:
Where from here?
Now that matches have been identified, there are several potential courses of action to take, depending on business requirements.
For example, data can be exported for further analysis. Within Denodo, results can be saved/exported to a delimited file for review or additional processing.
If this is a raw marketing list, redundant data could be eliminated to save outreach costs.
If this is a customer or prospect list, logic can be created to collapse redundant records in a single instance while maintaining important data from each of the records to maintain in the surviving record.
Not only can similarity keys be used to identify redundant records in a single Base View within Denodo, but multiple Base Views can have similarity keys appended, and then be used as the basis for matching across these Base Views. This provides much higher match rates when comparing and combining multiple data sources, rather than depending on exact matches as the basis of a Join.
This walkthrough is only one example of integrating Interzoid APIs within Denodo. There are also matching APIs that include specific matching algorithms for other types of data such as individual names (Bob = Robert, Johnson = Jonsen). Also, there are data enrichment APIs available to add additional data elements via the Cloud to existing data that can enhance various data initiatives.
The possibilities are limitless.
For more information, contact support@interzoid.com or visit https://www.interzoid.com
For a PDF version of the walkthrough, click here.
AI Interactive Data Client: Request and Receive Structured Data of Any Kind on Any Subject.
More...
Github Code Examples
More...
Generate your own Datasets: Retrieve Customized, Real-World Data on Demand as Defined by You
More...
High-Performance Batch Processing: Call our APIs with Text Files as Input.
More...
Try our Pay-as-you-Go Option
More...
Available in the AWS Marketplace.
More...
Free Trial Usage Credits
Check out our full list of AI-powered APIs
More...
Documentation and Overview
More...
Product Newsletter
More...